
Wittern, Christian, Kyoto University, Japan, cwittern@gmail.com
Introduction
The Daozang jiyao project aims not only at providing a new text-critical edition of an important collection of Daoist works, but also to serve as a research hub to any research concerning the collection and indeed Daoism in China since the 18th century1.
The Daozang jiyao 道臧輯要
The Daozang jiyao was first put together as a shorter compendium of the enormous Ming Dynasty Daozang, a collection that features some 1500 texts in thousands of scroll, hence its name, which translates as ‘Essential of the Daozang’. On closer examimnation, only about 60 percent of the text are from the earlier collection however, with much contemporary material added by the group around Jiang Yuanting 蔣元庭 (style Yupu 予蒲, 1755-1819), who reportedly added 79 texts not contained in the Daozang of the Ming during the Jiaqing era (1796-1820). This edition is still available at some libraries around the world, but inspection of these holdings revealed that almost none of these editions are identical; the texts included have been reshuffled, added or removed, woodblocks for missing pages have been recarved and new material has been added. To complicated matters even further, a reprint was done in Chengdu, Sichuan at the beginning of the 20th century, for which all text have been recarved according to the standards of the time, which resulted in a great number of changes to the text and the characters used for writing it. The collection now contains slightly more than 300 texts.
The whole complexity of the textual tradition came only gradually to the light through bibliographical research done by Monica Esposito and other project members, but it become also clear that the digital edition should not only be able to reflect the textual history accurately but should also be done in a way that allows modern day scholars to make full use of the digital edition, which meant that a modern text with normalized characters and modern interpunction had to be produced as well.
In addition to the digital text itself, a compendium with introductions to the texts in English and Chinese, as well a detailed catalog that details the content of the different editions are planned.
Towards a digital edition
Given the rather limited resources of the project, an efficient editing routine had to be established, some of which have been already reported in earlier presentations (Wittern 2009, 2010a, 2010b, 2010c).
A multitude of workflows
When the project started in 2006, a first draft of the text files would be made by a partner institution, the Institute for Chinese Literature and Philosophy, at Academy Sinica in Taiwan. In Kyoto, these text files were transformed to TEI conformant XML markup and then proofread and collated in one single step.
It proved to be very slow, first of all, because proofreading and collation are very different activities that are not easily performed together, but also because the editing of the XML source proved to be challenging for the members of the project, who where mostly specialists in Daoist studies.
As a remedy, the workflow of collation and proofreading was separated and performed with a specialised web application, that would allow the operators to see both the digital facsimile and the transcribed text on the same page. This application was developed based on a new text model, that allowed convenient handling even of characters, that could not be distinguished by there character encoding; details of this can be found in Wittern (2010a).
However, as it turned out, this was not yet the end of the work. For further steps, including the collation and subsequent structural markup of the texts, the web based user interface proved to be too limiting and time consuming to use, so another solution had to be found. We were reluctant to go back to editing the XML source, because that made it less convenient to align the text with the digital facsimiles, so a specialieed editor was preferred.
As it happened, around that time Emacs 23 was released, the first version which truly supported Unicode (although for some of the more arcane characters, a patch was still needed), so it became feasible to provide a customized interface for collation and structural editing.
Instead of trying to directly add the results of the collation to the XML file, as has been tried at the beginning of the project, we used now the ideas presented in Wittern (2011) to use the distributed version control system (DVCS) git to maintain the different versions of the text in different branches of the system and could thus easily align them. The algorithms to collate the texts are then partly drawn from Schmidt & Colomb (2009), a working session with a text to be processed is shown in Figure 1.
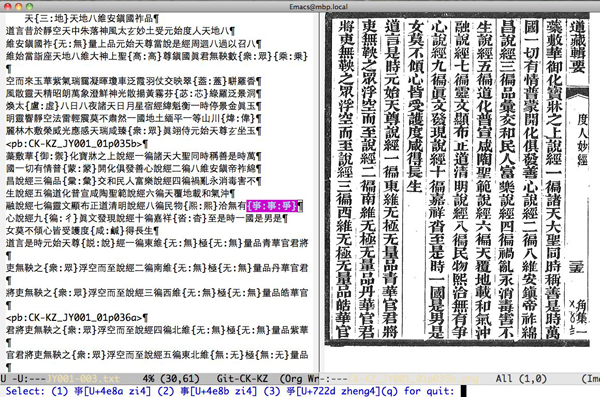
Figure 1: Work on the CK-KZ branch of the Daozang jiyao in a specialized Emacs editing mode
Towards publication
Both stages of the workflow, the web application and the Emacs bases solution have been built not only for internal use, but as a prototype for the eventual publication. This will not only allow us to make more efficient use of scarce resources, but also gives plenty of time to collect experience and improve the interface.
The expected publication will thus have two faces:
- For the casual user, a web based digital edition will provide easy access to all features of the edition without the need to install specialized software or learn a new tool.
- For scholars, who want to incorporate the texts into their own digital library and work on them using their own tools, a git repository will provide access to all ’branches’ of the edition and thus the full range of the established texts, including a normalized version.
- A master XML version, which documents the text using TEI conformant text-critical markup will also be available through a repository.
All of these editions will continue to be enhanced as the knowledge of the texts and their background increases. Since the texts are not simply made available for download, but are set up in a DVCS repository, not only can updates be integrated with local changes of users of the text, but they can make available other branches of the text through separate repositories.
Conclusions
Most of the text studied in the Humanities, and especially the material which is at the focus of this project, has come upon us through a long history of writing and re-writing of the text. To fully understand the text requires also an understanding of its tradition and the events that made it possible for us to hold the text in our hand, which might be excavations and spectacular finds or simply the steady and silent work of generations of curators and librarians that preserved the text for us. To realize its full potential, the digital text will thus not only try to reproduce one specific material edition, but allow the reader to look at versions of the text as they existed at certain points in history, so as to know what version of the text was current when it was read (and quoted) by such and such person. At the same time, the text will also be available together with other reference tools and research material in each of the Scholar’s digital library or ‘labs’.
Now, one of the real fundamental differences between digital text and printed texts as we have known it for centuries is the fact that the latter is a single product, whereas a text in the digital medium really wants to be seen in the context of all other texts, read in collaboration with other readers, in short requires a platform for scholarly editions, a ’Scholar’s Lab’, rather than simply a desk to be put on. How such a platform might be constructed and what it needs to do is a matter of heavy debate at the moment; I hope to voice my views at the presentation of this paper.
References
Burnard, L. and S. Bauman, eds (2008). TEI P5: Guidelines for Electronic Text Encoding and Interchange. Oxford: TEI Consortium.
Esposito, M. (2009). The Daozang Jiyao Project: Mutations of a Canon. Daoism: Religion, History and Society 1: 95-153.
Esposito, M. (2011). The Daozang jiyao 道臧輯要 as Receptacle to the Three Teachings in Qing Daoism: Lay and Clerical Authorities Face to Face. In Interactions between the Three Teachings. K. Mugitani (ed.). Vol. II. Kyoto: Dokisha, pp. 431-69.
Robinson, P. (2009). Towards a Scholarly Editing System for the Next Decades. In Sanskrit Computational Linguistics: First and Second International Symposia Rocquencourt, France, October 29-31, 2007 Prov- idence, RI, USA, May 15-17, 2008. Revised Selected Papers. Springer London: Springer, pp. 346-57.
Schmidt, D., and R. Colomb ( 2009). A data structure for representing multi-version texts online. International Journal of Human-Computer Studies 67(6): 497-514.
Shillingsburg, P. (2006). From Gutenberg to Google : electronic representations of literary texts. Cambridge: Cambridge UP.
Shillingsburg, P. (2009). How Literary Works Exist: Convenient Scholarly Editions. DHQ: Digital Humanities Quarterly 3(3).
Shillingsburg, P. (2010). How Literary Works Exist: Implied, Represented, and Interpreted. Text and Genre in Reconstruction: Effects of Digitalization on Ideas, Behaviours, Products and Institutions. Willard Mc-Carty (ed). Cambridge: Open Book Publishers.
Wittern, Ch. (2009). Digital Editions of premodern Chinese texts: Methods and Problems – exemplified using the Daozang jiyao. In Early Chán Manuscripts among the Dūnhuáng Findings – Resources in the Mark-up and Digitization of Historical Texts at University of Oslo, Sep. 28 to Oct. 3, 2009.
Wittern, Ch. (2010a). Mandoku – An Incubator for Premodern Chinese Texts – or How to Get the Text We Want: An Inquiry into the Ideal Workflow. Digital Humanities 2010. Kings College London.
Wittern, Ch. (2010b). Rebirth of the Daozang Jiyao – The never-ending Process of Creating a Digital Edition. In Cultural Crossings: China and Beyond in the Medieval Period Conference – Digital Projects in Asian Art and Humanities Workshop. Charlottesville.
Wittern, Ch. (2010c). Some Remarks Concerning Digital Editions of Premodern Chinese Texts. In: International Conference New Directions in Textual Scholarship. University of Saitama.
Notes
1.The project was initiated and led by Monica Esposito (1962-2011), who’s sudden parting came as a shock to all involved in the project. Like all outcomes of the project, this presentation is dedicated to her memory.