
Introduction
This paper will discuss a case study that uses theories of knowledge representation and research on phonetic symbolism to develop analytics and visualizations that help users examine aural and prosodic patterns in text. This use case is supported by the Andrew W. Mellon Foundation through a grant titled ‘SEASR Services.’ Other collaborators include Humanities professors from Stanford, George Mason University, and University of Illinois Urbana-Champaign. All of the use cases within the project include research on how humanities scholars can use textual analytics and predictive modeling with visualizations in order to help scholars interpret large digital collections. In particular, while this paper will briefly describe a new reading of Tender Buttons (1914) by Gertrude Stein that was facilitated by text analysis, predictive modeling, and visualization, but this discussion is primarily focused on how the theories, research, and methodologies that underpin this work facilitate digital diversity.
The logic and ontologies of aurality
Relying on the research of literary scholars and psychologists concerning how humanists make meaning with sound, we have chosen to use the logics and ontologies of aurality to model and analyze sound in text. If we are unclear about what we mean and how we mean when we seek to represent ‘sound,’ we discourage diverse readings from those who wish to understand the results of the computational analytics we apply to that model. In order to create a methodological approach that supports digital diversity, we seek to be transparent about the logics and ontologies of sound we are using. To this end, we have listed below each of the five roles that knowledge representation plays in a project according to Davis et al. (qtd. in Unsworth) and how these roles play out in the methodologies we have chosen to use in our use case.
(1) ‘A knowledge representation is most fundamentally a surrogate, a substitute for the thing itself’ (Davis et al. 1993).
In this project, we are defining sound as the pre-speech promise of sound as it is signified within the structure and syntax of text. Charles Bernstein focuses on the ‘aurality’ of text, which he calls the ‘sounding of the writing’ (Bernstein 13). ‘Orality,’ Bernstein writes, ‘can be understood as a stylistic or even ideological marker or a reading style; in contrast, the audiotext might more usefully be understood as aural – what the ear hears . . . Aurality precedes orality, just as language precedes speech’ (Bernstein 13). Using textual analytics to create a surrogate of potential sound is an essential aspect of the theory of aurality underpinning the methods in this project.
(2) Knowledge Representation ‘is a set of ontological commitments, i.e., an answer to the question: In what terms should I think about the world?’ (Davis et al. 1993).
In this project, we are committed to ontologies of sound that define sound as a meaningful aspect of text. This debate concerning whether or not sound makes meaning and how has a long history.1 These ideas, that the meaning of sound correlates to the structure of the text underpins the ontologies we have chosen for this project. Ultimately, the act of reading requires digital diversity since readers create their own sense making systems by making connections and understanding patterns. The same is true of reading sound: computers do an excellent job of modeling the features with which readers make these kinds of connections.
(3) Knowledge Representation ‘is a fragmentary theory of intelligent reasoning, expressed in terms of three components: (i) the representation’s fundamental conception of intelligent reasoning; (ii) the set of inferences the representation sanctions; and (iii) the set of inferences it recommends’ (Davis et al. 1993).
The above theories in aurality and research in phonetic and prosodic symbolism underpin our choice to use OpenMary, an open-source text-to-speech system, as a fundamental first step to generate the features that correspond to sound in texts. Developed as a collaborative project of Das Deutsche Forschungszentrum für Künstliche Intelligenz (GmbH) (German Research Center for Artificial Intelligence) Language Technology Lab and the Institute of Phonetics at Saarland University, OpenMary’s rule set or algorithm for ‘intelligent reasoning’ is based on the research of both linguists and computer scientists. Created to generate audio files of spoken text from written transcripts, OpenMary captures information about the structure of the text (features) that make it possible for a computer to read and create speech that is comprehensible to humans in multiple languages (German, British and American English, Telugu, Turkish, and Russian; more languages are in preparation). Specifically, OpenMary is a system that accepts text input and creates an XML document (MaryXML) that includes ‘tokens along with their textual form, part of speech, phonological transcription, pitch accents etc., as well as prosodic phrasing,’ all of which are important indicators of how the text could be ‘heard’ by a reader (‘Adding support for a new language to MARY TTS’) (see Figure 1)
(4) Knowledge Representation ‘is a medium for pragmatically efficient computation’ (Davis et al. 1993).
SEASR’s Meandre provides basic infrastructure for data-intensive computation, and, among others, tools for creating components and flows, a high-level language to describe flows, and a multicore and distributed execution environment based on a service-oriented paradigm. The workflow we created in Meandre processes each document in our collection through the OpenMary web service at a paragraph level to create a tabular representation of the data that also includes features that maintain the structure of the documents (chapter id, section id, paragraph id, sentence id, phrase id). Each word is parsed out into accent, phoneme and part-of-speech in a way that keeps the word’s association with the phrase, sentence, and paragraph boundaries. The ultimate benefit to creating this flow in Meandre is digital diversity: it is meant to be accessible to future users who wish to produce or tweak similar results (see Figure 2 and Figure 3).
In order to make comparisons evident with predictive modeling, we have also developed an instance-based, machine-learning algorithm for predictive analysis. We use an instance-based learning algorithm because it was thought to make similar mistakes as humans do (Gonzalez, Lerch, Lebiere). To focus the machine learning on prosody, we only used features that research has shown reflects prosody including part-of-speech, accent, stress, tone, and break index (marking the boundaries of syntactic units) (Bolinger). To further bias the system towards human performance, we selected a window size of fourteen phonemes, because it was the average phrase length and research has shown that human prosody comparisons are made at the phrase level (Soderstrom et al. 2003).
(5) Knowledge Representation ‘is a medium of human expression, i.e., a language in which we say things about the world’ (Davis et al. 1993).
An essential aspect of this project is ProseVis, a visualization tool we developed that allows a user to map the results of these analytics to the ‘original’ text in human readable form. This allows for the simultaneous consideration of multiple representations of knowledge or digital diversity. Digital Humanities scholars have also used phonetic symbolic research in the past to create tools that mark and analyze sound in poetry (Plamondon 2006; Smolinsky & Sokoloff 2006). With ProseVis, we also allow users to identify patterns in the analyzed texts by facilitating their ability to highlight different features within the OpenMary data (see Figure 4) as well as the predictive modeling results (see Figure 5) mapped onto the original text. The visualization renders a given document as a series of rows that correspond to any level in the document hierarchy (chapter/stanza/group, section, paragraph/line, sentence, phrase). In these ways, the reader can examine prosodic patterns as they occur at the beginning or end of these text divisions. Further, ProseVis represents the OpenMary data2 within ProseVis by breaking down the syllables into consonant and vowel components such as:
| Word | Sound | Lead Consonant | Vowel Sound | End Consonant |
| Strike | s tr I ke | s | I | Ke |
This breakdown provides the reader with a finer-grained level of analysis, as well as a simplified coloring scheme. See Figure 6 (beginning sound), Figure 7 (vowel sound), and Figure 8 (end sound).
Re-reading Tender Buttons by Gertrude Stein
Our predictive modeling experiment was to predict Tender Buttons out of a collection of nine books. The prediction was based on comparing each moving window of fourteen phonemes, with each phoneme represented solely by its aural features listed above. The hypothesis was that Gertrude Stein’s Tender Buttons (1914) would be most confused with The New England Cook Book (Turner 1905). Margueritte S. Murphy hypothesizes that Tender Buttons ‘takes the form of domestic guides to living: cookbooks, housekeeping guides, books of etiquette, guides to entertaining, maxims of interior design, fashion advice’ (Murphy 1991, p. 389). Figure 9 visualizes the results of our predictive analysis by showing the percentage of times the computer confuses its predictions for each of the nine books. In the visualization, row two shows the results for The New England Cook Book with Tender Buttons as the text that the computer ‘confuses’ with the highest percentage when trying to predict the cookbook. By modeling the possibility of sound with pre-speech features marking aurality, we are inviting diverse modes of discovery in textual sound.

Figure 1: Shows the phrase ‘Repeating then is in everyone,’ from Gertrude Stein’s text The Making of Americans
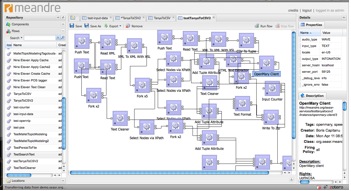
Figure 2: Shows the flow with the components that are used for executing OpenMary and post-processing the data to create the database tables
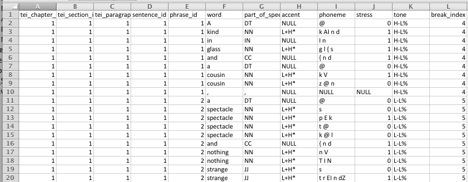
Figure 3: This is a sample of the tabular output of Tender Buttons by Gertrude Stein created within Meandre
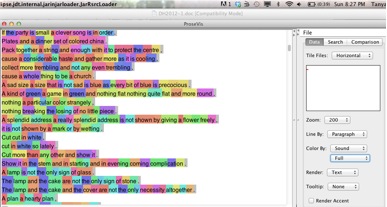
Figure 4: Sounds of each syllable in Tender Buttons by Gertrude Stein visualized using ProseVis
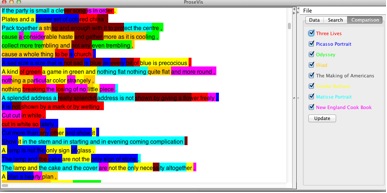
Figure 5: Predictive Modeling data comparing Tender Buttons to seven other texts visualized using ProseVis
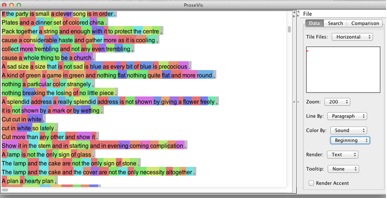
Figure 6: Beginning Sound of each syllable in Tender Buttons by Gertrude Stein visualized using ProseVis
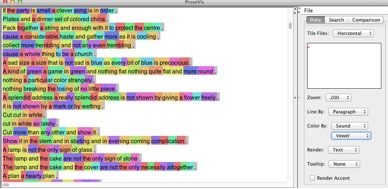
Figure 7: Vowel sound of each syllable in Tender Buttons by Gertrude Stein visualized using ProseVis
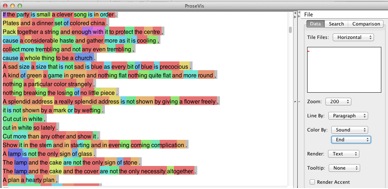
Figure 8: End sound of each syllable in Tender Buttons visualized using ProseVis
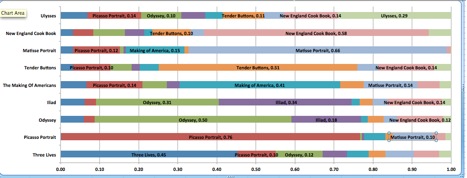
Figure 9: These are the results of a predictive modeling algorithm that was run on nine texts. Each color represents the percentage of times the algorithm predicts one of the nine in its attempt to pick a given text
References
Adding support for a new language to MARY TTS. MARY Text To Speech. Web. 8 Sept. 2011.
Bernstein, C. (1998). Close Listening: Poetry and the Performed Word. Oxford: Oxford UP.
Bolinger, D. (1986). Intonation and Its Parts: Melody in Spoken English. Stanford, CA: Stanford UP.
Clement, T. (2008). ‘A thing not beginning or ending’: Using Digital Tools to Distant-Read Gertrude Stein’s The Making of Americans. Literary and Linguistic Computing 23(3): 361-82.
Notes
1.See Bolinger, Cole, Newman, Ong, Plato Sapir, Saussure Shrum and Lowrey, and Tsur.
2.These sounds are documented herehttp://mary.opendfki.de/wiki/USEnglishSAMPA . However, over the course of testing ProseVis, we uncovered two additional vowel components, @U and EI, which are now included in the implementation.