
Introduction
Discussions about a markup language for the genetic encoding of manuscripts have reached a crucial point. The endeavours undertaken by a couple of notable projects over the last years promise to yield a new encoding standard for the description of the genesis of texts. In our talk we will survey the past and current states of affairs and outline some problems of genetic encoding within and without the framework of the Text Encoding Initiative (TEI).
Crucial issues in genetic encoding
Early conceptions of a computer-aided genetic edition trace back to the 1970s (Gabler 1998). The absence of any established standard for projects that aim to record revised manuscripts and genetic relations across numerous witnesses was still felt at the end of the 20th century. Through the 1990s and early 2000s, the then available TEI guidelines did not meet the requirements of genetic textual criticism, for genetic manuscripts often lack textual structure in a more conventional sense and show complicated series of revisions. This incompletenesses gave rise to the construction of the HyperNietzsche Markup Language (Saller 2003, esp. note 3) which was a kind of spin-off, but no sustainable alternative.1Some of the problems that led to HNML resolved themselves with the previous version of the Guidelines (Burnard et al. 2008: 72-78, 335-374). Other expectations, however (Vanhoutte 2002; Pierazzo 2009), remained unfulfilled:
- A documentary or ‘diplomatic’ transcription which focuses less on the as yet privileged textual structure of the examined material.
- The possibility to record the temporal course of the genesis of texts.
The ‘Encoding Model for Genetic Editions’ (Workgroup on Genetic Editions, 2010) was to satisfy both requests. Now that it has been largely incorporated in chapter 11 of the second version of ‘Proposal 5’ (Burnard et al. 2011), successes and shortcomings can be discussed. As for the documentary transcription, a way of encoding has been made possible which could not be thought of in former versions of the TEI Guidelines up to the first version of P5 (Burnard et al. 2008). However, the suggested approach to transcribe texts, taking into account the spatial distribution of the inscription falls short of completion (Brüning et al., forthcoming). The conceptual tension between the documentary and the textual perspective which gave rise to the proposed encoding model has become even more pronounced. As for the markup of textual alterations, it is not always clear how the newly introduced elements relate to well-established practice.2 The former stringency of chapter 11 of the Guidelines corresponded to the limited goal of providing ‘methods for encoding as broad a variety of textual features as the consensus of the community permits’ (Sperberg-McQueen et al. 1993). This consensus came to be known under the name of an ‘agnostic’ view on the issue of textuality. However, when chapter 11 was revised for the actual version, this consensus was tacitly and perhaps unawares abandoned. for the sake of much specific needs that parts of the new version of the chapter try to fulfill. Many of the needs which the newly introduced parts of the chapter try to fulfill are not covered by a broad consensus, but are based on very specific aims. Therefore the conceptional problems inherent in the genetic module cannot any longer be solved with reference to an alleged ‘agnostic’ basis. A discussion on the nature of text is not only of theoretical interest but also inevitable for practical reasons.
The dual nature of written texts
We would like to submit as a basic principle that any written text is, by virtue of being a linguistic entity, of a double-sided nature: First, it is by virtue of being a written text, a physical object that can be identified in space and time as a document or an inscription (the material or documentary dimension). Second, it is – by virtue of being a written text – an abstract object (the textual dimension), which has to be materialized in some way, not necessarily in one specific material form (Goodman 1977; Genette 1997). As can be learned from the epistemology of general linguistics (Saussure 1916: introduction, ch. 3; cf. Bouquet 1997), it is imperative for sound methodology to keep irreducible points of view distinct, each of which allows a coherent strategy of inquiry. Any attempt to collapse two entirely different dimensions into one, will ultimately run up on a reef of methodological incoherence. Within the digital humanities, the use of the word ‘text’ is often inspired by the way texts are represented in the digital code: as an ordered hierarchy of content objects (Renear et al. 1996) or as a strictly linear sequence of characters (cf. Buzzetti & McGann 2006: 60). But the hierarchical and/or linear representation of a text in a computer file is not and cannot by principle be a text in a linguistically respectable sense of the word (Sperberg-McQueen 1991: 34).
Consequences
Adherence to our basic principle will lead to some important consequences for encoding written texts and to some proposals for the application and further development of the available TEI Guidelines.
- The documentary perspective (1) takes the inscriptional point of view and focuses on the materialization of the text. The basic elements of this perspective are written letters and other inscriptional phenomena, such as cancellations and other sediments of the writing process. Inscriptional analyses can be focussed on units smaller than letters (e.g. allographic forms or elements below the niveau of the letter, see Feigs 1979). But due to the specific aims of our project, units smaller than letters are ignored. Letters can as well be regarded as linguistic units, and a linguistic understanding of what is written is a precondition for any manuscript to be deciphered. However, it is possible to disregard from this understanding for the purpose of a documentary edition. – The textual perspective (2) focuses on linguistic entities. Its basic elements are linguistic units. Depending on the perspective chosen, the following example has to be treated in two different ways:
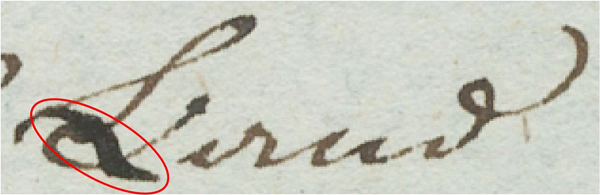
- From the documentary perspective, one letter (B) is changed into another (L). As said, even the fact that only a part of the original letter has been modified, might be of interest. But for the above reason, a replacement of letters is recorded. Therefore a documentary oriented encoding will usually look like this:3

- From the textual perspective, a whole word is substituted by another, ‘Band’ (ligament) by ‘Land’ (land):

This way of encoding focuses on the textual impact of the overwriting of (a part of) one letter: the substitution of a whole word. It does not mean that the textual perspective is confined to the level of word forms. In fact, sometimes only the spelling is corrected, and the alteration can very well be recorded on the level of graphemic units alone – no matter how many letters of the word have been replaced, no matter if the complete word is rewritten for the sake of clarity in the manuscript. However, in the given case the substitution does not concern only single letters but the linguistic unit of the next level (the word), although the scribe carefully avoided to deface the manuscript more than was necessary.
How can the sediments of the writing process and the textual genesis be given their equal due?
As is clear from the above example, not only the markup is concerned by the difference of the two perspectives but also the marked up content (‘BLand’ vs. ‘BandLand’). This is one of the reasons why a split-up of the encoding which we tried to avoid for a long time finally proved inevitable. We decided to introduce two separate transcripts: a documentary and a textual one (Bohnenkamp et al., forthcoming). The separate transcripts are the source for different parts of the edition: the documentary for the diplomatic rendering and the textual for the reading text and the apparatuses. The disadvantages of the split-up will be dealt with by help of automatic collation (Brüning et al., forthcoming). Logically, it is possible to integrate both perspectives in a single transcript, under the only condition that the markup is dominated by one of the two perspectives (Renear et al. 1996). Practically, however, it is very difficult to give adequate information on the writing process and on the text with equal regard to both sides. Detailed information of one of both will inevitably get lost. Furthermore, the intermingling of both perspectives complicates the subsequent data processing.
- From the documentary perspective, one letter (B) is changed into another (L). As said, even the fact that only a part of the original letter has been modified, might be of interest. But for the above reason, a replacement of letters is recorded. Therefore a documentary oriented encoding will usually look like this:3
- Thanks to the split-up, the documentary transcript is kept free from the limitations inherent to the markup of the textual structure, so that all the information that is needed to generate a satisfying diplomatic rendering can be placed. Likewise, the textual transcript is kept free from descriptive information about the record. In turn, an aspect of the linguistic structure can be taken into account the importance of which for genetic encoding has not yet found sufficient perception. As a concatenation of linguistic entities is not a mere sequence but a structure, it is necessary to distinguish between syntagmatically defined positions and paradigmatically selected items occupying them.4 In the above example, a position is initially occupied by the word ‘Band’, and subsequently by the word ‘Land’. The surrounding <subst>-tag indicates the paradigmatic relation between both items, although this is not explicit in the definition (Burnard et al. 2011: 1348).5 Problems arise in cases which deviate from the normal one-to-one-correspondence of items to positions, for example where the wording of the passage is held in abeyance as a consequence of an unfinished alteration.6 Introducing the differentiation between positions and items into genetic encoding might help to spot, clarify, and solve these problems.
References
Bohnenkamp, A., G. Brüning, S. Henke, K. Henzel, F. Jannidis, G. Middell, D. Pravida, and M. Wissenbach (forthcoming). Perspektiven auf Goethes Faust. Zur historisch-kritischen Hybridedition des Faust. Jahrbuch des Freien Deutschen Hochstifts 2011.
Bouquet, S. (1997). Introduction à la lecture de Saussure. Paris: Payot & Rivages.
Brüning, G., K. Henzel, D. Pravida (forthcoming). Rationale of multiple encoding in the Genetic Faust Edition. Journal of the Text Encoding Initiative (submitted).
Burnard, L., and S. Bauman, eds. (2004). TEI P4. Guidelines for Electronic Text Encoding and Interchange. XML-compatible edition. Oxford, Providence, Charlottesville and Bergen: The TEI Consortium.
Burnard, L., and S. Bauman, eds. (2008). TEI P5: Guidelines for Electronic Text Encoding and Interchange by the TEI Consortium. Oxford, Providence, Charlottesville, Nancy: Tei Consortium.
Burnard, L., and S. Bauman, eds. (2011). TEI P5: Guidelines for Electronic Text Encoding and Interchange by the TEI Consortium. Charlottesville: Text Encoding Initiative Consortium.
Buzzetti, D., and J. McGann (2006). Electronic Textual Editing: Critical Editing in a Digital Horizon. In L. Burnard, K. O’Brien O’Keeffe, and J. Unsworth (eds.), Electronic Textual Editing. New York: MLA, pp. 51-71.
Feigs, W. (1979). Deskriptive Edition auf Allograph-. Wort- und Satzniveau, demonstriert an handschriftlich überlieferten, deutschsprachigen Briefen von H. Steffens. Teil 1: Methode. Bern: Peter Lang.
Gabler, H. W. (1998). Computergestütztes Edieren und Computer-Edition. In H. Zeller and G. Martens (eds.), Textgenetische Edition. Tübingen: Niemeyer, pp. 315-328.
Genette, G. (1997). The Work of Art. Immanence and Transcendence. Ithaca, NY: Cornell UP.
Goodman, N. (1977). Languages of Art. An Approach to a Theory of Symbols. 2nd ed. Indianapolis, IN: Hackett.
Huitfeldt, C. (1998). MECS – a Multi-Element Code System (Version October 1998), Working Papers from the Wittgenstein Archives at the University of Bergen, 3. http://www.hit.uib.no/claus/mecs/mecs.htm (accessed 9 March 2012).
Owens, J. (1988). The Foundations of Grammar. An Introduction to Medieval Arabic Grammatical Theory. Amsterdam, Philadelphia: Benjamins.
Pierazzo, E. (2009). Digital Genetic Editions: The Encoding of Time in Manuscript Transcription, In M. Deegan and K. Sutherland (eds.), Text Editing, Print and the Digital World. Farnham and Burlington, VT: Ashgate, pp. 169-186.
Renear, A., E. Mylonas, and D. Durand (1996). Refining our Notion of What Text Really Is: The Problem of Overlapping Hierarchies. Research in Humanities Computing 4: 263-280. http://www.stg.brown.edu/resources/stg/monographs/ohco.html (accessed 9 March 2012).
Saller, H. (2003). HNML – HyperNietzsche Markup Language. Jahrbuch für Computerphilologie 5: 185-192. http://computerphilologie.uni-muenchen.de/jg03/saller.html (accessed 9 March 2012).
Saussure, F. de (1916). Cours de linguistique générale. Lausanne: Payot.
Sperberg-McQueen, C. M. (1991). Text in the Electronic Age: Textual Study and Text Encoding with Examples from Medieval Texts. Literary and Linguistic Computing 6: 34-46.
Sperberg-McQueen, C. M., and L. Burnard, eds. (1993). Guidelines for Electronic Text Encoding and Interchange (P2). Chicago, Oxford: Text Encoding Initiative. http://www.tei-c.org/Vault/Vault-GL.html(accessed 9 March 2012).
Sperberg-McQueen, C. M., and L. Burnard, eds. (1999). Guidelines for Electronic Text Encoding and Interchange. 1994. Revised Reprint. Chicago, Oxford: Text Encoding Initiative.
Vanhoutte, E. (2002). Putting Time back in Manuscripts: Textual Study and Text Encoding, with Examples from Modern Manuscripts, paper presented at the ALLC/ACH 2002, Tübingen, 25 July 2002. http://www.edwardvanhoutte.org/pub/2002/allc02abstr.htm (accessed 9 March 2012).
Workgroup on Genetic Editions 2010. An Encoding Model for Genetic Editions. http://www.tei-c.org/Activities/Council/Working/tcw19.html (accessed 9 March 2012).
Notes
1.‘HyperNietzsche’ nowadays operates under the name of ‘Nietzsche Source’, where the HNML based contents are regrettably cut off. They are still available by the following address: http://www.hypernietzsche.org/surf_page.php?type=scholarly. To become affiliated with the group of ‘Source’ projects, the ‘Bergen Text Edition’ of the Wittgenstein papers was converted from the specifically developed MECS to XML-TEI (P5) (http://www.wittgensteinsource.org/; Huitfeldt 1998). There are other ways to mark up transcriptions of modern manuscripts (see ‘Les manuscrits de Madame Bovary’, http://www.bovary.fr/; ‘Les Manuscrits de Stendhal’, http://manuscrits-de-stendhal.org/). But the set of tools provided by the TEI is clearly the one that is likely to become standard.
2.See esp. sect. 11.3.4.4 of the second version of P5 (Burnard et al. 367 sq.).
3.In fact, we do not use <subst> to record overwritings. Especially in the case of discarded starts overwriting letters do not positively substitute their predecessors. But we will not address this issue here.
4.he terminology of position-in-structure and of items-occupying-positions are very common in various schools of linguistics (cf. Owens 1988: 31-35) and in the computer sciences as well.
5.It is doubtful, therefore, if items which occupy ‘different positions’ (ibid., 352) can enter such a relation, as is, perhaps inadvertently, implied in the name of the newly introduced <substJoin> (ibid., 351 sq.).
6.For an example of the further, see sect. 11.3.4.6 of the TEI Guidelines (Burnard et al. 2011: 369). The suggested encoding (ibid., 370) neglects the symmetrical relation between the items ‘before’ and ‘beside’. From a textual point of view, the latter can be considered added only insofar as the former is considered deleted.