
Stokes, Peter, King’s College, London, UK, peter.stokes@kcl.ac.uk
As many hundreds of thousands of medieval manuscripts are now being digitised, with many millions of pages becoming available, the question of how to find specialised content in this material is becoming increasingly urgent. In this paper I present a new conceptual model for the description and therefore retrieval of features of handwriting in Western medieval script. Digital Humanities requires first a theoretical model which outlines all of the features of a given domain and the relationships between them (McCarty 2004), and this is the focus of the present paper. However, the implications of this work are very much wider: just as the TEI has lead to ‘a new data description language that substantially improves our ability to describe textual features’ (Renear 2004: 235), so the formal model of handwriting presented here sharpens and could even resolve long-standing problems in palaeographers’ own terminology and practice.1
The Problem
Common research questions in palaeography include finding examples of a particular way of writing a given letter, or scribes who constructed letters in particular ways. For example, it has been asserted that a specific form of t was used only by English scribes in the ninth century (Dumville 1984: 249-250), and that ‘Square’ features in Anglo-Caroline minuscule of the late tenth century is distinctive of Canterbury (Bishop 1972: xxii). These assertions have generally been made with little supporting evidence, in part because the corpus of surviving manuscripts is too large to support systematic analysis, but one should now be able to overcome this by producing an online resource for searching and viewing scribal practices and examples of script. This is an objective of the DigiPal project,2 which will provide an online catalogue of about 1,200 samples of English handwriting from the eleventh century, along with annotated digital images of about half of these. However, this objective is made very difficult by several factors. Image retrieval is very well studied, with approaches ranging from Content Based Image Retrieval (CBIR) such as that used by Google Images, to tagging with complex taxonomies like IconClass, as well as intermediate combinations of the two such as that provided by font identification software.3 However, CBIR cannot easily be tuned to scholars’ criteria if these do not match the machine’s perception of ‘content’. Similarly, systems like IconClass are very large, very intimidating, and require specialised training to use effectively. IconClass also depends on a shared vocabulary and this is famously absent from palaeography: the Comité international de paléographie latine was established in 1953 partly for this purpose but it has not produced even a draft document some fifty-eight years later.4 This can partly be overcome by thesauri which map equivalent terms from different practices, but an even more fundamental lack is that of a rigorous conceptual model for handwriting itself. The textual community has been debating ‘what text is’ for some time, partly because of the TEI (Pierazzo & Stokes 2011: 399-401), but no discussion like this has yet arisen in palaeography (though see Stokes 2010: 1228-1230). With neither a clear model nor a common vocabulary, it is hardly surprising that the few attempts at digital catalogues to date have been unsuccessful.5
The Model
To illustrate the difficulties, consider the following list of possible research questions:6
- Show me a list of all manuscripts containing the ‘Insular’ form of a (Fig. 1a).
- Show me images of all occurrences of the ‘Caroline’ form of s written by scribes who otherwise wrote Insular minuscule (Fig. 1b).
- Tell me which scribe(s) habitually wrote the ‘rounded’ form of a in combination with a hooked top-stroke of t (Fig. 1c).
- Give me images of all letters with forked ascenders (Fig. 1d).

Figure 1: Examples of Medieval Handwriting
Although these questions may look similar, they have a range of important differences which are largely concealed by the ambiguous word ‘letter’. The challenge is therefore how to model handwriting in sufficient detail to represent these nuances, considering not only a scribe’s general practice but also its specific instances. It requires first a clear distinction between script (‘the model which the scribe has in mind’s eye when he writes’), and (scribal) hand (‘what he actually puts down on the page’: Parkes 1969: xxvi). The word ‘letter’ is also ambiguous, and so further terms are useful here. Starting with the most concrete, a graph is an instance of the letter as written on the page. In contrast, an idiograph is ‘the way (or one of the ways) in which a given writer habitually writes’ a given letter, and an allograph is a recognised way of writing the given letter, as shared by a group rather than being distinctive of any given individual (Davis 2007: 254-255; cf. also Emiliano 2011).7 A grapheme is a letter-entity as an idealized, abstract, discrete, unit of a writing system. Also useful is Unicode’s character to refer to the intermediate level between grapheme (which by definition has no physical form) and allograph. Thus the grapheme <a> has (at least) two characters, ‘capital’ A and ‘small’ a. The second of these has many allographs, one of which is Insular a, this is normally found in the script known as Insular cursive minuscule; in Figure 1a and 1c we have two distinct allographs of a; and so on. Grapheme and character are both ‘emic’, whereas allograph, idiograph and graph are all ‘etic’.
Two further terms are required to describe specific details of letters. Component refers to the basic parts which make up characters, such as ascenders, descenders, serifs and so on; components may themselves have further components. Features are descriptive labels which may apply to one or more components: thus a descender may be straight or curved, long or short, and so on. Finally, we also need general stylistic features which may not refer to any specific component, such as the thickness and angle of the pen.
From these terms, a formal model has been developed which captures these entities and the relationships between them; this is represented in a simplified UML diagram in Figure 2 below.
According to this model, a grapheme has one or more characters, each character can be represented by an arbitrary number of allographs which in turn are represented by any number of idiographs and those in turn by graphs; a scribal hand comprises a set of graphs, scribal practice a set of idiographs, and so on. Each character, allograph, idiograph and graph can be made up of components, every component has at least one feature, and so on.
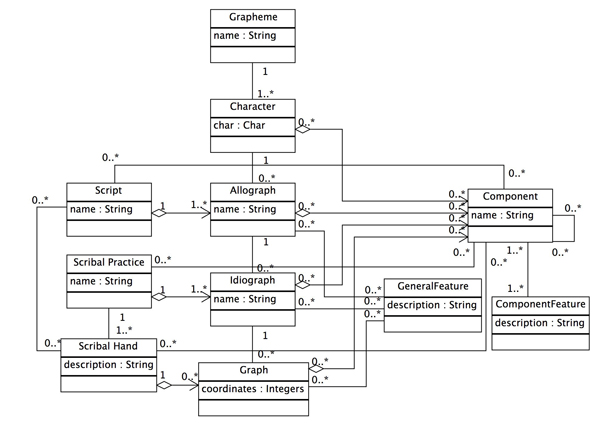 Figure 2: A Simplified UML Diagram showing the conceptual model of medieval handwriting
Figure 2: A Simplified UML Diagram showing the conceptual model of medieval handwriting
Significance and Usage
This model allows us to phrase palaeographical research questions much more precisely. It also allows structured descriptions of both habitual and specific writing-practices, thereby allowing complex queries. For example, we can specify:
- A set of possible characters and the components that each character must have.
- A script, namely a set of allographs which are normally written together, including their components and features.
- A scribal hand, namely the set of idiographs which a scribe normally uses.
- A set of graphs, for example those in an image of a particular manuscript page.
This model is also significant for capturing not only forms of letters but also specific stylistic features which apply across letters: not only particular forms of b, for example, but also the type of wedges on ascenders of any letter, or indeed wedges on ascenders of all letters exceptb.
An important further advantage is that if one level is fully defined then many details of the levels below that can be inferred automatically and so only exceptions need be recorded. For example:
- The character b has an ascender and a bowl.
- Insular minuscule script normally features wedges on ascenders.
- It follows from (1) and (2) that allographs of b in Insular minuscule will normally have wedges on ascenders.
This allows rapid data capture despite the highly detailed model – a crucial point in a context where many thousands of graphs and idiographs will need to be described in order to be worthwhile. One limitation of the model is that it allows one simply to record the presence of a feature, rather than (for example) numerical values to indicate ‘fuzzy’ cases where a feature is only partially present. The model could easily be adapted to accommodate this, but the increased time in data-entry would be prohibitive. Instead, in the implementation used for DigiPal, many features have n-ary distinctions instead: for example, ascenders can be wedged or clubbed or barbed or deeply-split or without decoration, and so on (see further Stokes 2011, Part v).
This paper will present the model and also demonstrate its use in practice through an annotation tool and search interface which are being developed for the DigiPal project. Reference will also be made to alternative uses which are being planned in the near future, including (we hope) application to Hebrew and Cuneiform script. The paper will also reflect on the process as an example of Digital Humanities bringing rigour to an existing discipline. McCarty has argued that modeling and the computer’s ‘demand for complete consistency’ leads directly ‘to the epistemological question of how we know what we know’ (2004). However, this question is itself fundamental to palaeography, where one of the biggest challenges has been to make explicit the apparently subjective judgments of experts. As Derolez wrote of these, ‘their great deficiency … lies in the difficulty of putting them into words’, and, more generally, he asked ‘whether morphological features [i.e. the shapes of letters] can be described in an unambiguous way’ (2003: 7). If a model such as this can achieve what fifty-eight years of the Comité could not then that would surely be a significant achievement in a field which has often viewed quantitative approaches and the Digital Humanities with significant mistrust (Derolez 2003: 7-9; Stokes 2009).
References
Bishop, T. A. M. (1971). English Caroline Minuscule. Oxford: Clarendon Press.
Davis, T. (2007). The Practice of Handwriting Identification. The Library, 7th series, 8: 251-276.
Derolez, A. (2003). The Palaeography of Gothic Manuscript Books. Cambridge: Cambridge UP.
Dumville, D. N. (1983). Motes and Beams. Peritia 2: 248-256.
Emiliano, E. (forthcoming 2011). Issues in the Typographic Representation of Medieval Primary Sources. In Y. Kawaguchi and M. Minegishi (eds.), Corpus Analysis and Diachronic Linguistics. Amsterdam: John Benjamins.
McCarty, W. (2004). Modeling: A Study in Words and Meanings. In S. Schreibman, R. Siemens and J. Unsworth, A Companion to Digital Humanities. Oxford: Blackwell. 254-270.
Parkes, M. B. (1969). English Cursive Bookhands 1250-1500. Oxford: Oxford UP.
Pierazzo, E., and P. A. Stokes (2010). Putting the Text Back into Context. In F. Fischer et al. (eds.), Kodikologie und Paläographie im Digitalen Zeitalter. Norderstedt: Books on Demand, vol. 2, pp. 397-430 http://kups.ub.uni-koeln.de/4360/.
Renear, A. (2004). Text Encoding. In S. Schreibman, R. Siemens and J. Unsworth, A Companion to Digital Humanities. Oxford: Blackwell, pp. 218-239.
Stokes, P. A. (2007/08). Palaeography and Image Processing. Digital Medievalist 3 http://www.digitalmedievalist.org/journal/3/stokes/.
Stokes, P. A. (2009). Computer-Aided Palaeography: Present and Future. In M. Rehbein et al. (eds.), Kodikologie und Paläographie im Digitalen Zeitalter. Norderstedt: Books on Demand, pp. 309-338 http://kups.ub.uni-koeln.de/volltexte/2009/2978/pdf/KPDZ_I_Stokes.pdf.
Stokes, P. A. (2010). Scripts. In A. Classen (ed.), Handbook of Medieval Studies. Berlin: de Gruyter, vol. 3, pp. 1217-1233.
Stokes, P. A. (2011). Describing Handwriting (Parts i–). London: King’s College http://digipal.eu/blogs/blog/describing-handwriting-part-i/.
Stokes, P. A. (forthcoming). Palaeography and the “Virtual library”. In B. Nelson and M. Terras (eds.), Digitizing Medieval and Early Modern Material Culture. Arizona: Center for Medieval and Renaissance Studies.
Unicode Consortium (2011). Glossary of Unicode Terms http://unicode.org/glossary/.
Notes
1.For initials expression of the ideas in this paper see the DigiPal blog (Stokes 2011).
3.http://www.iconclass.nl; http://www.identifont.com/; http://new.myfonts.com/WhatTheFont
4.http://www.palaeographia.org/cipl/ciplGen.htm. See further Derolez 2003: 6-9, and Stokes 2010: 1229-1230.
5.See the Palaeographic Catalogue at http://www.arts.manchester.ac.uk/mancass/C11database/letter_catalogue.php, and that by Stokes (2007/8: §§24-26). The shortcomings of both are discussed by Stokes (forthcoming).
6.These emerged from a workshop for the DigiPal project at King’s College London, 6 September 2011.
7.Idiograph should not be confused with ideograph, a ‘symbol that primarily denotes an idea or concept’ (Unicode 2011).