
Plutte, Christoph, Berlin-Brandenburg Academy of Sciences and Humanities, Germany, plutte@bbaw.de
Starting point
The Archiv-Editor1 is a multilingual desktop program created for working with prosopographical data and the Personal Data Repository (PDR), a server-client database system developed since 2009 by the DFG-Project Personal Data Repository2 at the Berlin-Brandenburg Academy of Sciences and Humanities (BBAW). Further development of the Archiv-Editor has become part of the DARIAH-DE initiative for digital infrastructure in 2011. The aim of the Person Data Repository is to provide a decentralized software system for research institutions, universities, archives, and libraries that allows combined access to biographic information from different data pools. It is especially designed to meet the requirements at the BBAW where divers research projects in Humanities collect personal data throughout their work. This data gathered from different research perspectives according to different research questions is usually stored in completely different formats ranging from text documents to relational databases and can hardly be maintained after the research project has finished. Since 2009, the Person Data Repository has provided a productive solution for storing, searching and exchanging person data including long term maintenance and tools such as the Archiv-Editor for working on the data and collecting new data.
The development of the PDR and the Archiv-Editor are based on the experiences that have been made at the BBAW since 2007 with a first version of the Archiv-Editor originally developed for the historical research project Preußen als Kulturstaat investigating archival materials (Czmiel & Holtz 2007). Concepts and approaches that had proved to be useful were generalized and implemented to be thoroughly customizable and extendable.
Challenges
The requirements of the starting point produce three main challenges for the data model and the architecture of the PDR and the Archiv-Editor. However, the Archiv-Editor’s interface design must to ensure usability over a complex data model because on the user side no special software knowledge can be presupposed. At the beginning of the PDR project evaluations of repository software and prosopographical databases were made (Körner, Plutte, Roeder & Walkowski 2010) that led to the decision to construct a new system and a new data entry interface rather than extending any existing software. Although this was an expensive approach the experiences with the first version of the Archiv-Editor were very promising and a redevelopment of the software could lead to a perfectly well fitting program, and this was proven to be true.
Enfolding the Heterogeneity of Data
Personal data from different research and editing projects at the BBAW are not only provided in different formats and have to be transformed into the PDR data model (Körner 2010), but come from divergent research perspectives and are semantically heterogeneous: The PDR integrates by means of transformation and the Archiv-Editor data from historians, musicologists, linguists, and philologists. The scientific cultures and disciplines at the BBAW and the kind of personal data and perspectives for which it is gathered differ very much. The PDR has therefore chosen to use a very open data model based on XML that does not narrow the type of information stored but allows the retention of any kind of statement about persons which can then be classified according to customizable semantic, time and spatial dimensions (Walkowski 2009). The approach does not define a person as single data record, but rather as compilation of all statements concerning that person. Thus, it is possible to display complementing as well as contradicting statements in parallel, which meets one of the basic challenges of biographic research. To enable a very deep classification of proper names and notions, words can be marked with a TEI3 compatible and fully customizable mark-up. Thus a very high level of atomization and complexity is implemented.
To ensure interoperability with other data stores transformation scripts are developed that allow the export of personal data into other standards such as TEI person description.
Multilingualism
Already in 2009 when the PDR started to develpe the repository software it began a cooperation with the Rom based German-French-Italian musicological project MUSICI4 (Roeder & Plutte 2010a). Therefore the Archiv-Editor was not only required to be translated into Italian, French and English but the classification schemas itself had to be designed to be language independent. Researchers in Rom want to classify their data in Italian but the data should be semantically compatible with those personal data collected at the BBAW in Berlin.
Usability
The complex data model of the PDR is diametrically opposed to the usability of the Archiv-Editor. The first step to usability was to encapsulate the XML – users do not see or edit XML. Since early 2011 when productive work with the Archiv-Editor began it has become clear that it is not enough to encapsulate XML: Research projects demanded to narrow the data entry fields and to enhance user guidance. In contrast to the – greatly appreciated – complexity and openness of the PDR data model a familiar database interface such as a formula with certain fields (Name, Profession etc.) was desired – as desktop program for offline work as well as an online version for web access.
Approaches to these challenges
Modularity
To combine theses divergent requirements the Archiv-Editor is designed modular. The Eclipse Rich Client Platform5 was chosen because of it’s extensibility and because it allows individual plugins for individual project requirements. While the PDR provides a solution to combine heterogeneous data und different research perspectives through a complex data model, the Archiv-Editor provides several general solutions plus individual adaption without cutting back the interoperability and exchangeability of the data.
One Archiv-Editor = 3 different Editors
Currently two desktop versions of the Archiv-Editor are provided and an online version will be published in 2012 porting both versions to the web.
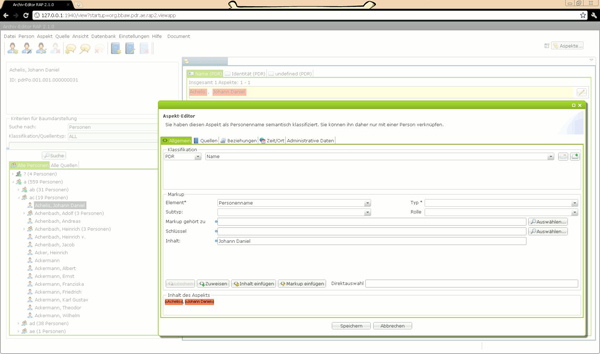
The lite version of the Archiv-Editor simplifies the appearance of the editor and provides only the very necessary functionality to make it easy for researchers to get started with the editor. The complex data model is represented in fully customizable formulas with user guidance in order to make the editor look as familiar as a simple database, although the openness of the data model is always in close reach through one click.
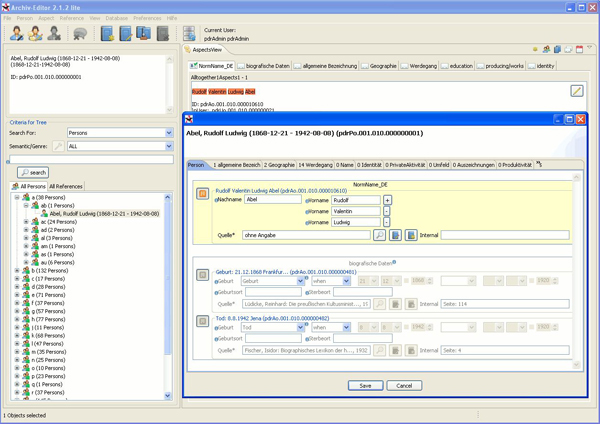
The advanced version of the Archiv-Editor contains all the functionality of the lite version and provides editors to fully edit all aspects of the data model. Besides the simple search different levels of advanced search are available as well as options for grouping and filtering statements. Furthermore, tools for datacleaning and automated PID (e.g. PND6, VIAF7, LCCN8) search are included.
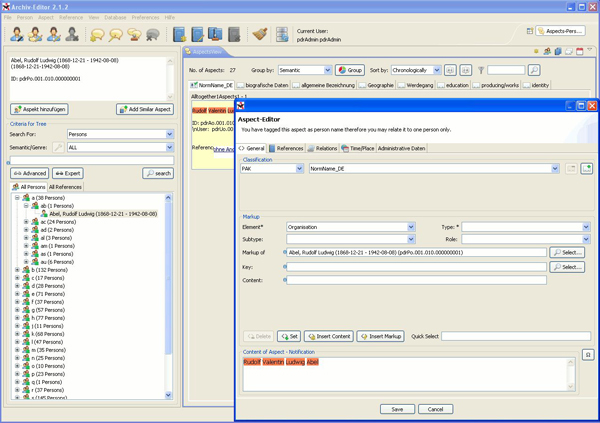
Archiv-Editor RAP is the online version of the Archiv-Editor and includes both the advanced version and the lite version. It uses the Eclipse Rich Ajax Platform9 Architecture to port the RCP Application to the web and hold most of the desktop functionality for working from anywhere and without prior installation. The Archiv-Editor RAP will be published in summer 2012.
Language independent classification schemes
Semantic classifications and ontologies are hardly language independent and notions and proper names do not retain exactly the same definition, connotation and discriminatory power when translated into another language. Furthermore, the mapping of classification systems is very problematic (van Ossenbruggen, Hildebrand & de Boer 2011). In order to ensure interoperability between classifications in different languages used in different projects (e.g. in Rom and Berlin) without having to map categories afterwards the Archiv-Editor and the PDR use a hierarchical classification system. Superordinate concepts and ordinate concepts such as ‘personName’, ‘placeName’, ‘profession’, ‘intellectual profession’, ‘musical profession’ are predefined using unique English terms and are translated for presentation in all interfaces to project specific languages. Subordinate concepts such as ‘violinist’, ‘violinista’ or ‘cantate’ can be added according to project specific requirements without prior standardization. Thus classifications in different languages can be compared on high and mid-level terms without any mapping efforts. Although the classification system is thus not thoroughly standardized and internationalized it combines both the need for interoperability and the openness to easily manageable project specific extensions. Even if subordinate concepts such as ‘violinist’ and ‘violinista’ can not directly be mapped they can be identified as subcategories of the same language independent superordinate concept ‘musical profession’.
References
Czmiel, A., and B. Holtz (2007). Quellenarbeit im Projekt ‘Preußen als Kulturstaat’ – Strukturierte Informationserfassung mit dem ‘Archiv-Editor’. Beiträge der Tagung .hist 2006 – Geschichte im Netz: Praxis, Chancen, Visionen. vol 10, part vol. I.
Körner, F. (2010). Datenarchäologie und Datenaufbereitung, digiversity, September 30. http://digiversity.net/2010/datenarchaeologie/.
Körner, F., C. Plutte, T. Roeder, and N.-O. Walkowski (2010). Software-Evaluation für ein Personendaten-Repositorium. Research Paper, Berlin. <urn:nbn:de:kobv:b4-opus-15111>
Neumann, G., F. Körner, T. Roeder, and N.-O. Walkowski (2010). Personendaten-Repositorium (PDR): Berlin-Brandenburgische Akademie der Wissenschaften. Jahrbuch 2010, Berlin, pp. 320-326.
Plutte, C. (2011). Archiv-Editor – Software for Personal Data. In S. Gradmann, F. Borri, C. Meghini, and H. Schuldt (2011). Research and Advanced Technology for Digital Libraries, Berlin: Springer, pp. 446-448.
Roeder, T., and C. Plutte (2010a). Un repositorio per i musici stranieri nell’Italia dal 1650 al 1750. Concezione del database del progetto ANR/DFG: Deutsches Historisches Institut in Rom, January 27.
Roeder, T., and C. Plutte (2010b). Die MUSICI-Datenbank. Personendaten-Repositorium und Archiv-Editor: Jahrestagung der Gesellschaft für Musikforschung, Deutsches Historisches Institut in Rom und Ècole Française de Rome, November 04–05.
Roeder, T. (2009). Kooperationsmöglichkeiten mit dem Personendaten-Repositorium der BBAW: <urn:nbn:de:kobv:b4-opus-9231>
Schattkowsky, M., and F. Metasch (2008). Biografische Lexika im Internet. Thelem, Dresden.
Van Ossenbruggen, J., M. Hildebrand, and V. de Boer (2011). Interactiv Vocabulary Alignment. In S. Gradmann, F. Borri, C. Meghini, and H. Schuldt (2011). Research and Advanced Technology for Digital Libraries, Berlin: Springer, pp. 296-307.
Walkowski, N.-O. (2009). Zur Problematik der Strukturierung und Abbildung von Personendaten in digitalen Systemen: <urn:nbn:de:kobv:b4-opus-9221>
Walkowski, N.-O. (2011). Das Konzept einer polysemischen Datenbank und seine Konkretisierung im Personendaten-Repositorium der BBAW. In G. Braungart, P. Gendolla, and F. Jannidis (2011). Jahrbuch für Computerphilologie – online.
Notes
1.http://pdr.bbaw.de/software/ae
5.http://wiki.eclipse.org/Rich_Client_Platform
6.http://www.d-nb.de/standardisierung/normdateien/pnd.htm