
Wiegand, Frank, Berlin-Brandenburgische Akademie der Wissenschaften, Germany, wiegand@bbaw.de
Project
The DFG-funded project Deutsches Textarchiv (German Text Archive, DTA1) started in 2007 and is located at the Berlin-Brandenburgische Akademie der Wissenschaften (Berlin-Brandenburg Academy of Sciences and Humanities, BBAW2). Its goal is to digitize a large cross-section of German texts from 1650 to 1900. The DTA presents almost exclusively the first editions of the respective works. Currently there are more than 700 texts available (i. e. 500 million characters), most of them transcribed by non-native speakers using the double keying method.
The DTA provides linguistic applications for its corpus, i. e. serialization of tokens, lemmatization, lemma-based and phonetic search, and rewrite rules for historic spelling variation.
Each text in the DTA is encoded using the XML/TEI-P5 format. The markup describes text structures (headlines, paragraphs, speakers, poem lines, index items, etc.), as well as the physical layout of the text down to the position of each character on a page.
Problem Statement
Even though our corpus of historic text exhibits very good quality, many errors still occur in the transcription, in the markup, or even on the level of presentation. Due to the heterogeneity of the corpus, e. g. in terms of text genres (novels, prose, scientific essays, linguistic reference works, cookbooks, etc.) there is a strong demand for a collaborative, easy to use quality assurance environment.
As of October 2011, the corpus consists of more than 260,000 pages (half a billion characters), several gigabytes of XML. Even though our digitization providers assure an accuracy rate of 99.95 %, many errors remain undetected, not to mention problems in the presentation layer of the DTA or workflow mistakes.
There are many kinds of possible errors in our transcribed texts: transcription errors (e. g. due to illegible text or text written in foreign scripts like hebrew, greek, runic, etc.) sometimes require specialized background knowledge, so we created various assorted tools to aid users in finding potentially problematic spots in our texts, and to help transcribers to obtain better and faster results.
In addition, DTA provides an interface DTAE3 for the integration of external text transcriptions along with the corresponding images and metadata. These transcriptions should be encoded in XML/TEI using the DTA ‘base format’4
Quality assurance (QA) also has to take into account other levels of error prone representations and tasks, namely metadata, XML/TEI annotation, HTML presentation (and other media), and the robustness of workflow. DTAQ is our QA system dealing with all these potential errors: They need to be reported, stored and fixed.
DTA Quality Assurance
DTAQ5 is a browser-based tool to find, categorize, and correct various kinds of errors. Using a simple authentication system combined with a fine-grained access control system, new users can easily be added to our QA system. The GUI of our tool is highly customizable, so we can offer diverse views of our source images, transcriptions, and presentations.
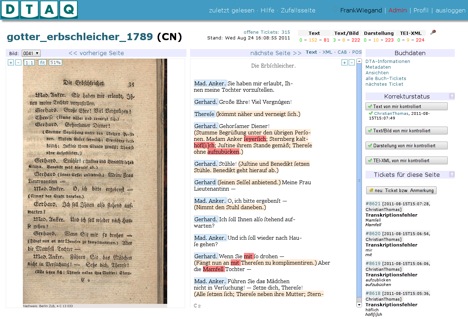
Figure 1: DTAQ: parallel view of image and rendered transcription
Our linguistic tools (CAB,6 PoS-tagging) are integrated into this environment, not only to check their performance for errors, but also to provide alternate views of our texts. To avoid unnecessary repetitions in proofreading, users can mark pages as proofread. Using this technique, we are also able to provide several quality levels of our pages or books. All tickets and proofread pages are stored in a database, thus DTAQ provides in-depth analysis and visualisation of the accuracy of the DTA corpus.
The backend of DTAQ is built upon many open source packages, using Perl as a glue language. The system runs on Catalyst7, connects to a PostgreSQL database via the DBIx::Class ORM and builds its web pages with Template Toolkit. The frontend makes heavy use of jQuery and Highcharts JS to create a very interactive and responsive user interface.
Our XML/TEI files are automatically split up into individual pages and stored in a git8 repository. The development of DTAQ itself also occurs within a distributed git repository.
Poster and tool demonstration
Our poster will show the DTAQ workflow patterns, along with a live demonstration showing the various views, tools, and powerful features of the quality assurance platform.
References
Geyken, A., et al. (2011). Das Deutsche Textarchiv: Vom historischen Korpus zum aktiven Archiv. In S. Schomburg, C. Leggewie, H. Lobin, and C. Puschmann (eds.), Digitale Wissenschaft. Stand und Entwicklung digital vernetzter Forschung in Deutschland, 20./21. September 2010. Beiträge der Tagung. 2., ergänzte Fassung. Köln: HBZ, pp. 157-161.
Jurish, B. (2010). More than Words: Using Token Context to Improve Canonicalization of Historical German. Journal for Language Technology and Computational Linguistics (JLCL) 25(1).
Jurish, B. (2012). Finite-state Canonicalization Techniques for Historical German. PhD thesis, Universität Potsdam 2012 (urn:nbn:de:kobv:517-opus-55789).
Unsworth, J. (2011). Computational Work with Very Large Text Collections. Interoperability, Sustainability, and the TEI. Journal of the Text Encoding Initiative 1 (http://jtei.revues.org/215, 2011-08-29).
Notes
1.Deutsches Textarchiv (German Text Archive): http://www.deutschestextarchiv.de/.
2.Berlin-Brandenburgische Akademie der Wissenschaften: http://www.bbaw.de/.
3.DTAE (DTA Extensions): http://www.deutschestextarchiv.de/dtae.
4.DTAB (DTA “base format”): http://www.deutschestextarchiv.de/doku/basisformat.
5.DTAQ (DTA Quality Assurance): http://www.deutschestextarchiv.de/dtaq.
6.For each text, DTAQ provides a transformation to a normalised modern spelling form using the Cascaded Analysis Broker CAB, cf. Jurish:2010 + Jurish:2012.
7.Catalyst MVC Framework, written in Perl: http://www.catalystframework.org/.
8.git, a distributed version control system written by Linus Torvalds et al.: http://git-scm.com/