
Project background and focus of the paper
In view of the increasing amount of reading and writing that people do on the Internet, corpus designers who set out to provide balanced corpora that include all relevant text types of contemporary language should also include samples of genres of computer-mediated communication (CMC) such as e-mail, weblogs, microblogging on Twitter, discussion boards and wiki discussions, chats and instant messaging conversations, and communication in social network sites. In our paper we present selected aspects of an ongoing project that aims at building a reference corpus of German CMC, called DeRiK (‘Deutsches Referenzkorpus zur internetbasierten Kommunikation’).1 DeRiK is a joint initiative of TU Dortmund University and the Berlin-Brandenburg Academy of Sciences and the Humanities (BBAW). The corpus will be integrated into the lexical information system provided by the BBAW project Digitales Wörterbuch der deutschen Sprache (DWDS, www.dwds.de).2
In our paper we will focus on the role of the DeRiK component in the DWDS framework (section 2) and on CMC-specific issues of corpus annotation (section 3).
Integrating CMC discourse into a corpus of contemporary German: motivation and application fields
DWDS (www.dwds.de) is a lexical information system developed by and hosted at the BBAW. The system offers one-click-access to three different types of resources (Geyken 2007):
a) lexical resources: a common language dictionary,3 an etymological dictionary, and a thesaurus;
b) corpus resources: a balanced reference corpus (called ‘DWDS core corpus’) of German ranging from 1900 up to now, a set of additional newspaper corpora, and specialized corpora;
c) statistical resources for words and word combinations.
These resources are displayed alongside one another in separate panels (cf. Fig. 1). The system offers the choice among several views, i.e. between several profiles with predefined panel combinations.
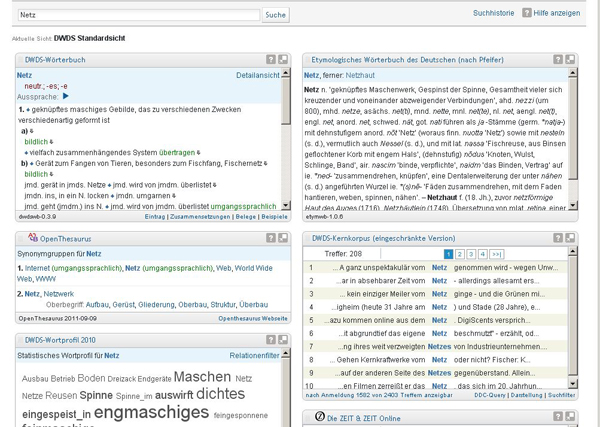
Figure 1: Web frontend of the DWDS system (http://www.dwds.de)
The CMC component DeRiK (‘Deutsches Referenzkorpus zur internetbasierten Kommunikation’) will be integrated into this framework both as an independent panel and as a subcorpus of the DWDS core corpus. The sampling of the CMC genres in DeRiK is guided by the findings of the ‘ARD/ZDF-Onlinestudie’, a German online usage survey conducted once per year (www.ard-zdf-onlinestudie.de). The findings of this survey allow us to derive a key for the composition of our corpus. However, for practical reasons the project will set out to acquire data of only those CMC applications on the Internet for which the users have explicitly granted permission for (re-)distributing and (re-)using their written utterances for non-commercial purposes/academic research.4 The first partial corpus of DeRiK will include discourse from Wikipedia talk pages, a selection of forum and weblog discussions, chat conversations, and postings of selected Twitter users who have licensed their tweets under Creative Commons. We hope that in the long term changes in IPR restrictions within the domain of discourse on the Internet will enable us to apply more principled methods of data sampling.
The integration of the CMC reference corpus into the DWDS system may be valuable for various research and application fields, for example:
a) Language variation, language change and stylistics: A general-language corpus that includes a CMC component will provide a broad empirical basis (a) for further, corpus-based investigations of the usage and dissemination of CMC-specific phenomena across linguistic varieties and digital genres, and (b) for comparative analyses of the features of CMC discourse and of “traditional” written genres (e.g. newspaper, fiction, scientific writing, nonliterary prose); it will thus facilitate to track and describe how new linguistic patterns and communicative genres emerge.5
b) Lexicology and lexicography: Besides genre-specific discourse markers and netspeak jargon (like ‘lol’ laughing out loud or ‘imho’ in my humble opinion), new vocabulary is characteristic for CMC discourse, e.g. ‘funzen’ (an abbreviated variant of ‘funktionieren’ to function) or ‘gruscheln’ (a function of a German social network platform, most likely a blending of ‘grüßen’ greet and ‘kuscheln’ cuddle). There are also CMC-specific processes of lexical-semantic changes, e.g. the broadening of the concept of ‘Freund’ (friend). Up-to-date lexical resources should document and describe these tendencies by integrating CMC data into their data basis. Once the first partial corpora of the DeRiK corpus are made available in the DWDS system, it is intended to extend the DWDS dictionary component with entries describing new lexemes that have evolved from CMC discourse. In addition, the DWDS corpus system will then allow one to track how new vocabulary from CMC discourse (such as the examples mentioned above) spreads into ‘traditional’ genres (e.g. newspaper, fiction, nonliterary prose).
c) Language teaching: CMC has become an important part of everyday communication. Language- and culture-specific properties of CMC should thus also be regarded in communicative approaches to Second Language Teaching. In this context, the DeRiK corpus and the documentation of CMC vocabulary in the DWDS dictionary may be useful resources. In school teaching, students with German as a native language may use the DWDS system to compare written language with CMC and to explore how style varies across different genres.
Annotation of CMC-specific phenomena
One advantage of integrating DeRiK into the DWDS system is that users can profit from the DWDS corpus annotation and querying facilities: The corpus resources which are currently available in the DWDS system are lemmatized with the TAGH morphology (cf. Geyken & Hanneforth 2006) and tagged with the part-of-speech tagger moot (cf. Jurish 2003). The corpus search engine DDC (Dialing DWDS Concordancer) supports linguistic queries on several annotation levels (word forms, lemmas, STTS part-of-speech categories), filtering (e.g. by text type) and sorting options.
Since all corpus resources in the DWDS system are encoded according the guidelines of the Text Encoding Initiative (TEI-P5), the project aims to use and customize TEI for the appropriate base-level annotation of the CMC sub-corpus. For this purpose, we have developed a TEI-compliant annotation schema that
- provides a macro-structure of CMC discourse which should cover as many genres as possible (see section 3.1);
- provides a suggestion for the description of CMC-specific phenomena which is oriented mainly on surface features (for instance, the annotation will cover interaction signs of various types; see section 3.2 for details).
The TEI-related details of this schema are described in Beißwenger et al. (2012).6 The discussion in this paper will focus on two annotation issues: The representation of CMC-specific micro- and macrostructures (section 3.1) and the annotation of typical ‘netspeak’ elements (section 3.2).
Annotation of CMC-specific micro- and macrostructures
We introduced the category posting as a basic element to capture CMC micro- and macrostructures. A posting is defined as a content unit that is being sent to the server ‘en bloc’. Postings can usually be recognized by their formal structure, even if they have different forms and structures across CMC genres. This facilitates the automatic segmentation and annotation of CMC micro- and macrostructures.
We use the term microstructure to refer to the internal structure of postings. There are cases in which a posting consists of exactly one portion of text. In other CMC genres, e.g. in discussion groups, postings may contain divisions and markup used by the author to structure their content.
We use the term macrostructure to describe how the postings are sequenced. While microstructures are generated by an individual author, macrostructures do not emerge from the actions of just one user but from all posting activities of all users involved in a CMC conversation plus server routines for ordering the incoming postings.
In our TEI schema, we represent structures on the microstructure level (which result from the planning and composition decisions of one author) using the <p> element (‘paragraph’) from the TEI standard. Structures on the macrostructure level, in contrast, are described using the <div> element (‘division’). In addition, we differentiate between two major types of CMC macrostructures:
- logfile structures, which arrange the postings in a linear chronological order based on when they reached the server.
- thread structures, which arrange the postings in a sequence and use two dimensions with specific semantics: the above/below dimension representing a temporal ‘before/after’ relation; the left/right dimension (by indentation), which usually symbolizes the topical affiliation of one posting to a previous posting.
Annotation of interaction signs
The corpus-based investigation of ‘netspeak’ jargon is interesting in many research contexts (style variation and language change, discourse management, language teaching etc.). Our annotation schema copes for a set of ‘netspeak’ phenomena which we term ‘interaction signs’. The term builds on the category ‘interaktive Einheiten’ which has been introduced in the Grammatik der deutschen Sprache, a three-volume scientific grammar of the German Language (cf. Zifonun et al. 1997), to classify interjections (such as ‘hm’ or ‘oh my god’) and responsives (such as ‘yes’ and ‘no’) in spoken discourse7. In contrast to part-of-speech-categories, interaction signs are not syntactically integrated and do not contribute to the compositional structure of sentences. In spoken discourse, they serve as devices for conversation management, i.e. they can be used to express reactions to the partners’ utterances or to display the speaker’s emotions. Our category ‘interaction sign’ includes interjections and responsives as well as four CMC-specific classes (cf. Fig. 2):
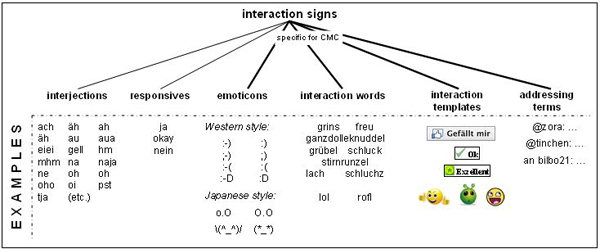
Figure 2: Typology of interaction signs (with examples)
- Emoticons are iconic units that have been created with the keyboard and which typically serve as emotion or irony markers or as responsives. Being of iconic origin, the use of emoticons is not restricted to a specific language. However, different styles of emoticons exist – e.g, Western style emoticons such as
 ,
,  ,
,  or the , or Japanese style emoticons such as (^_^), (^_^)/, (*_*).
or the , or Japanese style emoticons such as (^_^), (^_^)/, (*_*). - Interaction words are symbolic linguistic units whose morphologic construction is based on a word or a phrase. They may describe gestures or facial expressions, e.g. *g* (< “grins” grin), *fg* (< fat grin), *s* (< smile), or they are used for the simulation of actions and events.
- Interaction templates are units that the user does not generate with the keyboard but which are generated automatically from a file with a previously prepared text or graphical element after the user has activated a template. Due to their generation from predefined templates, we do not classify them as emoticons, even though some of them may have similar functions. Amongst others, this category includes *.gif files. Many of them portray not just facial expressions but can depict almost everything; in the case of animated graphics they can even portray entire scenes as moving pictures.
- Addressing terms are units which are used to address an utterance to a particular interlocutor. The most widely used form here is the one made out of the <@>-character together with a specification of the addressee’s name.
Conclusion and outlook
Up to now, many assumptions about the Internet’s impact on language change have been based upon small datasets. As a new component within the DWDS system, the DeRiK corpus is meant to be a resource for the investigation of language usage in CMC genres on a broader empirical basis. The annotation schema sketched in section 3 is used and evaluated in the ongoing work of the DeRiK project. The categories proposed in this schema will have to be further discussed within the CMC community. We consider the development of this schema as a first step towards the development of an annotation standard that will facilitate cross-language, cross-genre, and micro-diachronic investigations of CMC phenomena on the basis of corpora. The schema focuses on linguistic aspects, but it is open for extensions motivated through other fields of research, i.e. cultural studies or sentiment analysis.
References
Beißwenger, M. (2000). Kommunikation in virtuellen Welten: Sprache, Text und Wirklichkeit. Stuttgart: Ibidem.
Beißwenger, M., and A. Storrer (2008). Corpora of Computer-Mediated Communication. In A. Lüdeling and M. Kytö (eds.), Corpus Linguistics. An International Handbook, vol. 1. Berlin: de Gruyter, pp. 292-308.
Beißwenger, M., M. Ermakova, A. Geyken, L. Lemnitzer, and A. Storrer (2012). A TEI schema for the Representation of the Computer-mediated Communication. TEI (Text Encoding Initiative) Journal. (submitted 2012).
Biber, D., et al. (1999). Longman Grammar of Spoken and Written English. Edinburgh: Pearson.
Biber, D., et al. (2002). Longman Student Grammar of Spoken and Written English. Edinburgh: Pearson.
Blake, B. J. (2008). All About Language. New York: Oxford UP.
Crystal, D. (2001). Language and the Internet. Cambridge: Cambridge UP.
Crystal, D. (2011). Internet Linguistics. A Student Guide. New York: Routledge.
[DUDEN-45] DUDEN (1995). Die Grammatik. 5th ed. Mannheim: Bibliographisches Institut.
[DUDEN-47] DUDEN (2005). Die Grammatik. 7th ed. Mannheim: Bibliographisches Institut.
Geyken, A. (2007). The DWDS corpus: A reference corpus for the German language of the 20th century. In Ch. Fellbaum (ed.), Collocations and Idioms. London: Continuum, pp. 23-40.
Geyken, A., and Th. Hanneforth (2006). TAGH – A Complete Morphology for German based on Weighted Finite State Automata. In: A. Yli-Jyrä, L. Karttunen, and J. Karhumäki (eds), Finite State Methods and Natural Language Processing – Proceedings of FSMNLP, 5th international workshop, Helsinki 2005, Heidelberg: Springer (= Lecture Notes in Artificial Ingelligence 4002), pp. 55-66.
Greenbaum, S. (1996). The Oxford English Grammar. New York: Oxford UP.
Herring, S. C. (1996). Introduction. In: S. C. Herring (ed.), Computer-Mediated Communication. Linguistic, Social and Cross-Cultural Perspectives. Amsterdam/Philadelphia: John Benjamins, pp. 1-10.
Herring, S. C., ed. (1996). Computer-Mediated Communication. Linguistic, Social and Cross-Cultural Perspectives. Amsterdam/Philadelphia: John Benjamins.
Herring, S. C., ed. (2010). Computer-Mediated Conversation, Part I. Special Issue of Language@Internet 7. http://www.languageatinternet.org/articles/2010 (accessed 11 March 2012)
Jurish, B. (2003). A Hybrid Approach to Part-of-Speech Tagging, Final report. Project ‘Kollokationen im Wörterbuch’. Berlin-Brandenburgische Akademie der Wissenschaften, Berlin. http://www.ling.uni-potsdam.de/~moocow/pubs/dwdst-report.pdf (accessed 11 March 2012)
McArthur, T., ed. (1998). Concise Oxford Companion to the English Language. Oxford: Oxford UP.
Reynaert, N., O. Oostdijk, H. de Clercq, et al. (2010). Balancing SoNaR: IPR versus Processing Issues in a 500-Million-Word Written Dutch Reference Corpus. In Proceedings of the Seventh conference on International Language Resources and Evaluation (LREC’10). Paris, 2693-2698. Online: http://eprints.eemcs.utwente.nl/18001/01/LREC2010_549_Paper_SoNaR.pdf
Runkehl, K., T. Siever, and P. Schlobinski (1998). Sprache und Kommunikation im Internet. Überblick und Analysen. Opladen: Westdeutscher Verlag.
Schiffrin, D. (1986). Discourse markers. Cambridge: Cambridge UP.
Storrer, A. (2012, in press). Sprachstil und Sprachvariation in sozialen Netzwerken. In B. Frank-Job, A. Mehler, and T. Sutter (eds.), Die Dynamik sozialer und sprachlicher Netzwerke. Konzepte, Methoden und empirische Untersuchungen an Beispielen des WWW. Wiesbaden: VS Verlag für Sozialwissenschaften.
[TEI-P5] TEI Consortium (eds., 2007). TEI P5: Guidelines for Electronic Text Encoding and Interchange. http://www.tei-c.org/Guidelines/P5/ (accessed 11 March 2012).
[WDG]: Klappenbach, R., and W. Steinitz, eds. (1964-1977). Wörterbuch der deutschen Gegenwartssprache (WDG). 6 Bände. Berlin: Akademie-Verlag.
Werry, C. C. (1996). Linguistic and interactional features of Internet Relay Chat. In S. C. Herring (ed.), Computer-Mediated Communication. Linguistic, Social and Cross-Cultural Perspectives. Amsterdam/Philadelphia: John Benjamins, pp. 47-63.
Zifonun, G., L. Hoffmann, B. Strecker, et al., eds. (1997). Grammatik der deutschen Sprache. 3 Bände. Berlin, New York: de Gruyter.
Notes
1.Cf. http://www.empirikom.net/bin/view/Themen/DeRiK. The project is embedded in the scientific network ‘Empirische Erforschung internetbasierter Kommunikation’ (http://www.empirikom.net/), funded by the Deutsche Forschungsgemeinschaft (DFG).
2.Another corpus of contemporary language which aims to include a CMC subcorpus is the Dutch SoNaR project (Reynaert et al. 2010).
3.This dictionary is based on a six-volume paper dictionary, the Wörterbuch der deutschen Gegenwartssprache (WDG, en.: ‘Dictionary of Contemporay German’) published between 1962 and 1977 and compiled at the Deutsche Akademie der Wissenschaften (cf. [WDG]).
4.This is typically communicated by assigning certain subtypes of the ‘Creative Commons’ License to CMC documents or to web applications which specify the terms of (re-)use and (re-)distribution of their content.
5.Overviews of the features of CMC discourse from a linguistic perspective can be found, e.g., in Herring (ed., 1996, 2010), Werry (1996), Runkehl et al. (1998), Beißwenger (2000), Crystal (2001, 2011), Beißwenger & Storrer (2008), and Storrer (2012). The DeRiK corpus will include annotations of selected phenomena which are often described as being typical for language use on the Internet.
6. The RNG schema file, a TEI-compliant ODD documentation as well as encoding examples are available at http://www.empirikom.net/bin/view/Themen/CmcTEI.
7.In other grammars these units are described as interjections (e.g., Greenbaum 1996; McArthur et al. 1998; Blake 2008) or Interjektionen (DUDEN-47), inserts (Biber et al. 1999, 2002), discourse markers (Schiffrin 1986), discourse particles or Gesprächspartikeln (DUDEN-45).