
Introduction
The availability of large-scale text corpora in digital form and the availability of sophisticated analysis and querying tools have profoundly influenced linguistic research over the past three decades. The present paper uses this eHumanities methodology in order to automatically detect and analyze valence compounds for German. Valence compounds (in German: Rektionskomposita) such as Autofahrer ‘car driver’ have been subject to extensive research in the German linguistics. They are composed of a deverbal head (Fahrer ‘driver’) and a nominal non-head (Auto ‘car’). As the corresponding verb fahren ‘to drive’, from which Fahrer is derived, governs its accusative object Auto, the compound Autofahrer is considered a valence compound.
The automatic detection and semantic interpretation of compounds constitutes an important aspect of text understanding for a language like German where compounding is a particularly productive means of word formation and accordingly occurs with high frequency. Baroni et al. (2002) report that almost half (47%) of the word types in the APA German news corpus, which they used as training material for a word prediction model for German, are compounds.
Due to their productivity, compounds in German do not form a closed class of words that can be listed in its entirety in a lexicon. Rather, as Lemnitzer (2007) has shown, new German compounds are coined daily, and some of them attain sufficient frequency to be eventually included in print dictionaries such as the Duden. Novel compounds that are not yet listed in a dictionary pose a particular challenge for natural language processing systems that rely exclusively on dictionaries as their underlying knowledge source for word recognition.
Since the analysis of compounds constitutes a major challenge for the understanding of natural language text, the structural analysis and the semantic interpretation of compounds have received considerable attention in both theoretical and computational linguistics. Syntactic analysis of compounds focuses on the correct (left- vs. right- branching) bracketing of the constituent parts of a given compound, e.g., [[rock music] singer] vs. [deputy [music director]]. Research on the semantic interpretation of compounds has focused on the semantic relations that hold between the constituent parts of a compound. The present paper focuses entirely on the semantic interpretation of compounds; however see Henrich and Hinrichs (2011) for previous research on the syntactic analysis of nominal compounds in German.
Corpus-Based Experiments
The aim is to determine whether corpus evidence can form the basis for reliably predicting whether a given complex noun is a valence compound or not. For example, if we want to determine whether the complex noun Taxifahrer is a valence compound, we inspect a large corpus of German and investigate whether there is sufficient evidence in the corpus that the noun Taxi can be the object of the verb. The question of what exactly constitutes sufficient corpus evidence is of crucial importance. Three different measures were applied to answer this question:
- Relative frequency: The percentage of the verb-object pairs in the corpus among all co-occurrences of the two words in the same sentence with any dependency relations,
- The association score of mutual information for the verb-object pairs, and
- The Log-Likelihood ratio for the verb-object pairs.
The measure in (1) above constitutes a simplified variant of the data-driven approach that Lapata (2002) applied for the purposes of automatically retrieving English valence compounds from the British National Corpus.
The starting point of the corpus-based experiments was a list of 22,897 German complex nouns and the Tübingen Partially Parsed Corpus of Written German (TüPP-D/Z).1 This corpus consists of 200 Mio. words of newspaper articles taken from the taz (‘die tageszeitung’) and is thus sufficiently large to provide a reliable data source for the experiments to be conducted. The TüPP corpus was automatically parsed by the dependency parser MaltParser (Hall et al. 2006).
Each of the 22,897 potential valence compounds has been split into its deverbal head and its nominal modifier with the help of the morphological analyzer SMOR (Schmid et al. 2004). For example, the compound Autofahrer receives the analysis Auto<NN>fahren<V>er<SUFF><+NN> in SMOR. From the TüPP corpus, all occurrences of those object-verb pairs are extracted from those corpus sentences where either the verb in the sentence matches the deverbal head of the complex noun (e.g., fahren) or the accusative object of the sentence matches the nominal modifier (e.g., Auto) of the compound.
Figure 1 gives an example of the type of dependency analysis of the MaltParser from which the verb-object pairs are extracted. The dependency analysis represents the lexical tokens of the input sentence as nodes in the graph and connects them with vertices which are labeled by dependency relations. Recall that the MaltParser annotation is performed automatically and thus not 100% accurate. In the case of the sentence Aber dann würde doch niemand mehr Auto fahren. (‘But then, no one would drive cars anymore.’) shown in Fig. 1, mehr is erroneously attached to the noun Auto instead of to the noun niemand.
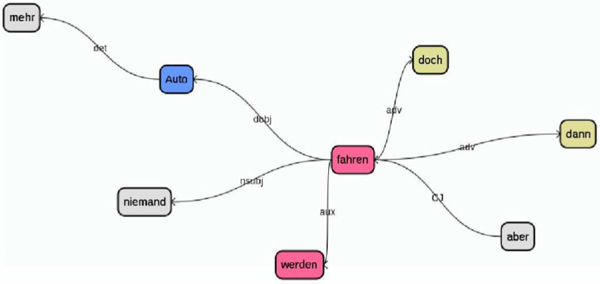
Figure 1: A MaltParser dependency graph for a TüPP corpus sentence Aber dann würde doch niemand mehr Auto fahren
Both the mutual information and the log-likelihood measures determine the association strength between two words by considering the relative co-occurrences shown in the contingency table (Table 1).
| Accusative object Auto | Accusative object ¬Auto | |
| Verb fahren | Auto fahren | Fahrrad fahren |
| Verb ¬fahren | Auto waschen | Wäsche waschen |
The association strength increases for both measures the more the number of co-occurrences in the upper left corner of the contingency table outweighs the number of occurrences in the remaining cells.
Evaluation
From the list of 22,897 putative valence compounds, a balanced sample of 100 valence compounds and 100 non-valence compounds was randomly selected in order to be able to evaluate the effectiveness of the methods described above. Each entry in this sample was manually annotated as to whether they represent valence compounds or not. The sample as a whole serves as a gold standard for evaluation.2
For all three association measures described above recall, precision, and F-measure were computed. The results are shown in Fig. 2, 3, and 4, for log-likelihood, mutual information, and relative frequency, respectively. The first two measures yield a continuous scale of association strength values. The graphs in Fig. 2 and 3 plot, on the x-axis, association strength thresholds that correspond to a quantile between 100% and 10% of the values observed for these measures. The y-axis shows the corresponding effect on precision and recall for each measure.
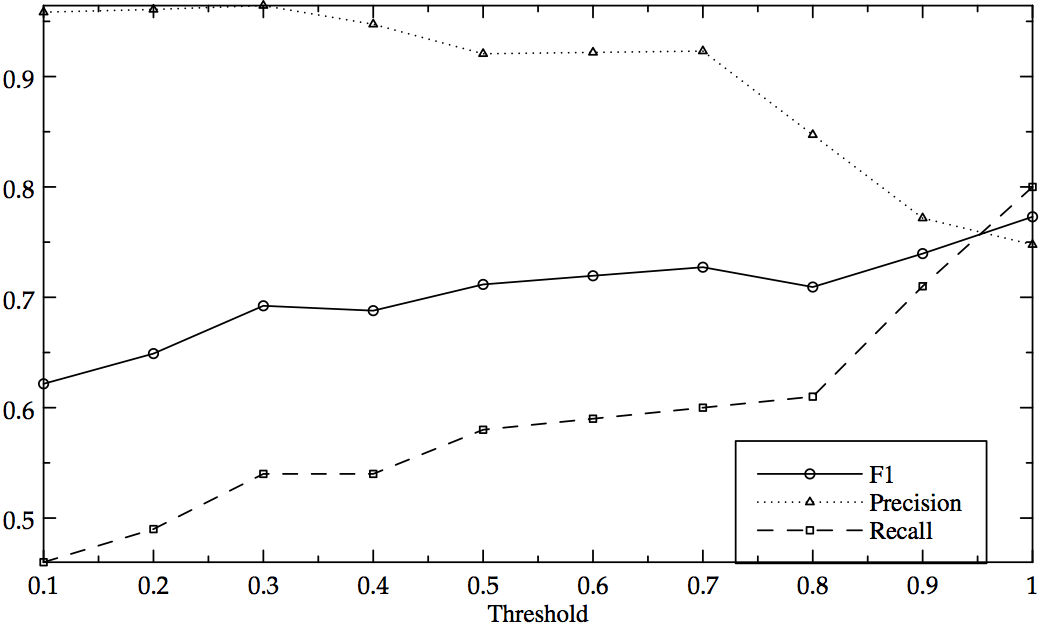
Figure 2: Precision, Recall, and F1 for Log-Likelihood
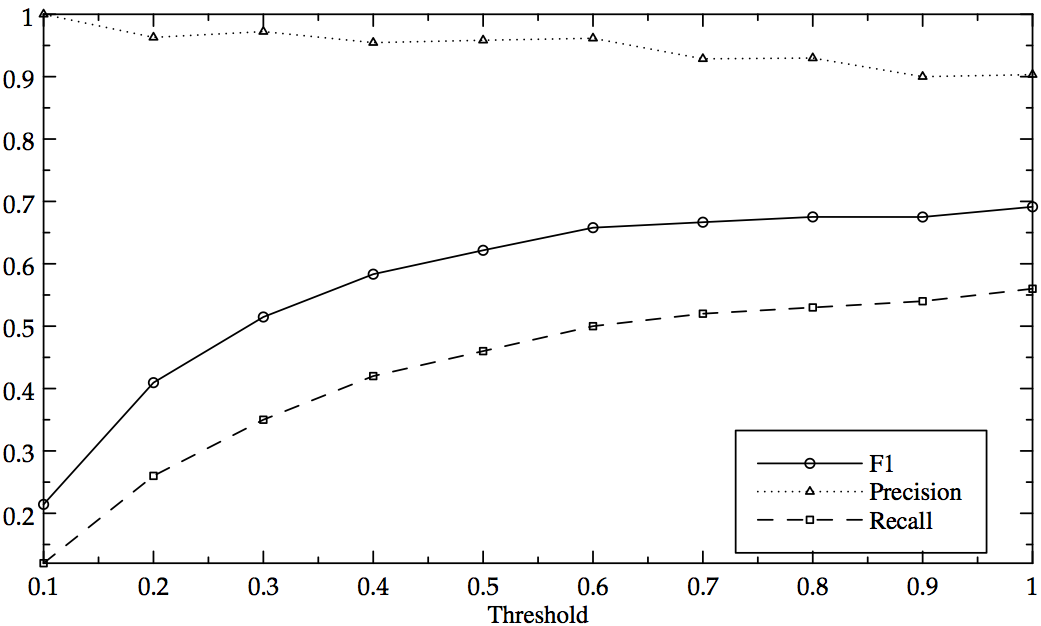
Figure 3: Precision, Recall, and F1 for Mutual Information
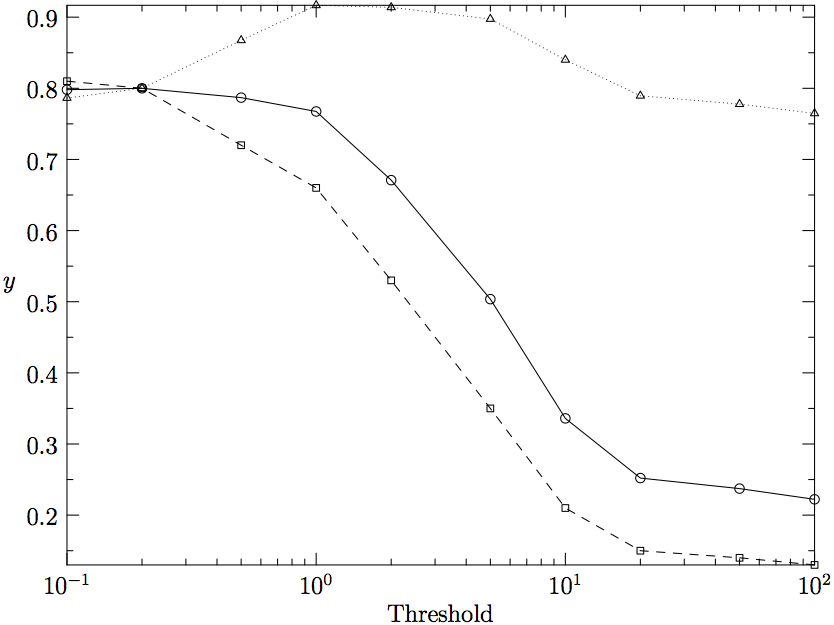
Figure 4: Precision, Recall, and F1 for Relative Frequency
For the relative frequency approach (Fig. 4) the decision to reject or accept a candidate pair is made by weighting occurrences as a verb-object pair against occurrences in other contexts. The weights can consist of any value between zero and positive infinity. Unlike the association measures (log-likelihood and mutual information), this approach does not yield a ranking of candidates; in consequence, the precision (shown in Fig. 4) does not decrease monotonically but shows an optimal parameter setting for values between 1.0 and 2.0.
The results show that all three measures are independently valuable in the corpus-based identification of valence compounds. Relative frequency and log-likelihood yield the best recall (up to 81%), while mutual information affords the best precision (up to 100%). Future research will address the effective methods for combining the complementary strengths of all three measures into an optimized classification approach.
In sum, the eHumanities method presented in this paper for the identification of valence compounds in German has proven effective and can thus nicely complement traditional methods of analysis which focus on the internal structure of valence compounds as such.
References
Baroni, M., J. Matiasek, and H. Trost (2002). Predicting the Components of German Nominal Compounds. In F. van Harmelen (ed.), Proceedings of the 15th European Conference on Artificial Intelligence (ECAI). Amsterdam: IOS Press, pp. 470-474.
Hall, J., J. Nivre, and J. Nilsson (2006). Discriminative Classifiers for Deterministic Dependency Parsing. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics (COLING-ACL) Main Conference Poster Sessions, pp. 316-323.
Henrich, V., and E. Hinrichs (2011). Determining Immediate Constituents of Compounds in GermaNet. In Proceedings of Recent Advances in Natural Language Processing (RANLP 2011), Hissar, Bulgaria, pp. 420-426.
Lapata, M. (2002). The disambiguation of nominalizations. Computational Linguistics 28(3): 357-388.
Lemnitzer, L. (2007). Von Aldianer bis Zauselquote: Neue deutsche Wörter, woher sie kommen und wofür wir sie brauchen. Tübingen: Narr.
Schmid, H., A. Fitschen, and U. Heid (2004). SMOR: A German Computational Morphology Covering Derivation, Composition, and Inflection. In Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC 2004). Lisbon, Portugal, pp. 1263-1266.
Notes
1.See http://www.sfs.uni-tuebingen.de/en/tuepp.shtml
2.Precision measures the fraction of retrieved valence compounds that are correctly analyzed. Recall measures the fraction of actual valence compounds that are retrieved.