
Chong, Dazhi, Old Dominion University, USA, dchong@odu.edu Coppage, Samuel, Old Dominion University, USA, scoppage@odu.edu Gu, Xiangyi, Old Dominion University, USA, xxxgu001@odu.edu Maly, Kurt, Old Dominion University, USA, maly@cs.odu.edu Wu, Harris, Old Dominion University, USA, hwu@odu.edu Zubair, Mohammad, Old Dominion University, USA, zubair@cs.odu.edu
Introduction and Prior Work
In previous Digital Humanities conferences we presented the Facet System, a system that improves browsing and searching of a large collection by supporting users to build a faceted (multi-perspective) classification schema collaboratively (Georges et al. 2008; Fu et al. 2010). The system is targeted for multimedia collections that have little textual metadata. In summary, our system (a) allows users to build and maintain a faceted classification collaboratively, (b) enriches the user-created facet schema systematically, and (c) classifies documents into an evolving facet schema automatically. It is hoped that through users’ collective efforts the faceted classification schema will evolve along with the users’ interests and thus help them navigate the collection. For the browsing and classification interfaces of the Facet System see Fig. 1 and Fig. 2. This paper discusses scalability challenges and improvements made to the system, cloud deployment, user studies and evaluation results.
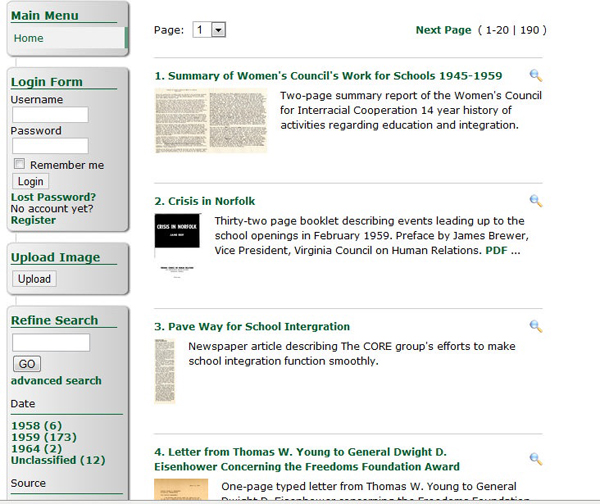
Figure 1: Browsing of the system enabled by user-evolved faceted classification
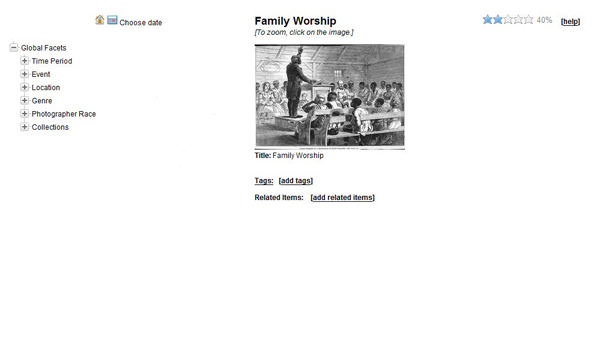
Figure 2: The click-and-drag classification screen
Scalability Issues and System Improvement
Our Facet System allows users to collaboratively evolve a common, global schema that contains facets (perspectives such as colour) and categories (such as red and green in the colour facet) for a large multimedia collection, using a wiki-inspired interface. The global schema can then used by any users for browsing or searching the collection. The variety of user perspectives increases with the number of users. Even though we have taken measures to cure and reduce the global schema, we find that the global schema alone faces limitations in supporting a large number of users. Many users prefer to focus on a smaller subset of the schema or collection. To address this issue, we have improved the user interface to allow users switch between global and personal schemas. The personal schema allows users to organize digital documents in their own way. A group of people can share the same personal schema which applies to a subset of the large digital collection. On the backend, we developed a ‘merging’ algorithm that automatically enriches the global schema by merging items, categories and facets from personal schema into the global schema. The algorithm applies statistical techniques to item-category associations, category-subcategory and category-facet associations, and Wordnet-based similarities. Figure 3 shows both global and personal schemas that can be utilized by individual users or user groups. More technical details will be presented at the conference.
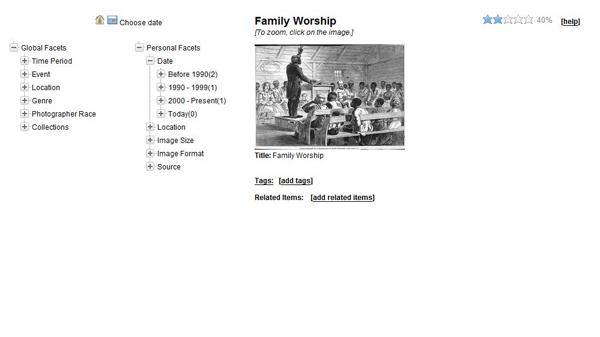
Figure 3: Global and personal (or local) schemas
Cloud Deployment
A large repository with millions of multimedia items may consume terabytes of storage. To support millions of users, the system needs to be partitioned, mirrored, or load balanced across an array of servers. When user traffic and growth trends are not perfectly predicable, cloud computing is not only the most cost effective but also likely the only viable option.
After evaluating several cloud service providers, we find that Microsoft Azure Cloud provides the best cost-effectiveness for us to host large digital repositories that require scalable database support as well as network bandwidth. Our Facet System was built on an open source technology stack including Joomla, PHP and MySQL. Joomla is a leading open source content management system implemented in PHP. Initially we deployed the system on two server layers, Web (Joomla/PHP) and Database (MySQL) layers, utilizing Web and Worker roles in the Azure cloud (see Fig. 4). The scalability and manageability of the MySQL database turned out to be prohibitive. We found that true database scalability can be accomplished only by cloud-tailored solutions such as Microsoft SQL Azure. We spent significant efforts in porting Joomla from MySQL to Microsoft SQL Azure. In addition, we moved Joomla’s session management from the default storage in operating system files to Azure storage, to enable stateless load balancing across many servers on the Web layer. During the conference we will present more technical details which may benefit users of Joomla and other open source content management systems.

Figure 4: The deployment architecture in Microsoft Azure
Evaluation and user studies
We evaluated the system using 15 classes (different sessions of a university-wide undergraduate introductory information technology class) during Spring 2011, and continue the evaluation with 22 classes during Fall 2011 semester using the cloud deployment of our system. Each class has around 30 students. The system was used to teach the digital humanities and social computing component of the class, by asking students to collaboratively curate a special library collection of un-cataloged local newspaper clippings and images on African American activism in United States. We captured detailed usage information as users completed a series of tasks involving searching, classification, tagging and voting (providing feedback on digital items and metadata). Each class of students work as a group using a single personal schema, which may be better labeled as ‘local schema’ in the future to avoid confusion. A backend algorithm periodically merges categories and facets from these local schemas into the global schema. While global schema is useful, we find that the students spend a lot of efforts on curating the collection through building the local schemas for their own classes. Therefore we refer to our current system a Social Curation System. The performance of the system and cloud deployment proves to be satisfactory and actually exceeded our expectation in certain aspects.
A common challenge to curating digital collections is the lack of expertise necessary to classify, catalog and create metadata structures for such collections. The evaluation shows the feasibility of social curation by non-expert users supplemented by suitable algorithms for reinforcing, combining and judging user created associations and tags. From a social science perspective, we are interested in the relationship between student’s prior experience and attitudes about social computing and their current behavior in a social curation environment. We used a pre-usage instrument to assess the users’ prior experience with common social sites, then a post-usage instrument to measure post-usage attitudes and conceptual understanding of the resulting metadata among the users. We also measured students’ knowledge in digital humanities and African American activism before and after the system usage. The change in perceived usefulness of the archive from the beginning of the experiment to the end was also measured. We will present the result of the data analysis at the conference and hope that it will help future designs and implementations of socially curated archives.
Related Work and Conclusion
There are many large scale multimedia collections on the Internet. Few of them, however, contain library-grade metadata for digital items. Researchers have proposed or studied how to build large, curated collections on the Internet. Recent Digital Humanities conferences have showcased efforts in trying to utilize multiple organizations’ collaborative efforts in building federated or related collections (Timothy et al. 2011). Our project utilizes cloud computing to explore the scalability limitations of collaborative curation, and implement algorithmic approaches to synthesize individual users’ or groups’ curation efforts. Our work on backend algorithms are build upon recent advancements in ontology building, text categorization and link mining (e.g. Wu et al., 2006a, 2006b; Heymann et al. 2006; Joachims et al. 1998;Schmitz et al. 2006). Evaluation results show the promise of our social curation approach.
Funding
This work was supported by the National Science Foundation [ grant number 0713290].
References
Fu, L., K. Maly, H. Wu, and M. Zubair (2010). Building Dynamic Image Collections from Internet. Digital Humanities 2010, London, UK, 2010.
Georges, A., K. Maly, M. Milena, H. Wu, and M. Zubair (2008). Exploring Historical Image Collections with Collaborative Faceted Classification. Digital Humanities 2008, Oulu, Finland, 2008.
Heymann, P., and H. Garcia-Molina (2006).Collaborative Creation of Communal Hierarchical Taxonomies in Social Tagging Systems. Stanford Technical Report InfoLab.
Joachims, T. (1998) Text categorization with support vector machines. 10th European Conference on Machine Learning. London, 1998.
Schmitz, P., and Yahoo! Research (2006). Inducing Ontology from Flickr Tags. Workshop in Collaborative Web Tagging, WWW 2006, 2006, Edinburgh, UK.
Cole, T., N. Fraistat, D. Greenbaum, D. Lester, and E. Millon (2011). Bamboo Technology Project: Building Cyberinfrastructure for the Arts and Humanities. Digital Humanities 2011, Stanford, CA, 2011.
Wu, H., M. Zubair, and K. Maly (2006). Harvesting Social Knowledge from Folksonomies. ACM 17th Conference on Hypertext and Hypermedia, 111-114, Odense, Demark, August 20-25, 2006.
Wu, H., M. Gordon, K. DeMaagd, and W. Fan (2006). Mining Web Navigations for Intelligence. Decision Support Systems 41(3): 574-591.