
Barner-Rasmussen, Michael, Danish National Research Foundation Centre for Language Change In Real Time, Denmark, mbr@hum.ku.dk
The motivation to write this paper stems from an experience we had a few years ago. We needed to digitize a large reference work called Danmarks Stednavne (DS 1922-2006, ‘Place Names of Denmark’) which contains most, if not all, of the place names in Denmark.
We wanted and needed the end result to be in a database-style format, that is, capturing or otherwise marking the place name of each record, and including all the sources, scholarly interpretations, historical names and dates, and so on. But we discovered that no one was willing to sign up for the task, even though we had a quite decent budget (capped at approximately $20 a page and 10,000 pages in total).
We were uniformly informed that the task was too complex.
This paper presents the solution we came up with: we bought a TEI Tite (Trolard 2009) encoded digitization procedure from an outside vendor, but did the post processing into a database format ourselves.
Cost and practicality have weighed heavily and are important aspects of the methodology presented. It might seem more interesting to try and create some genetic, self-learning algorithm to automatically eke out the semantics of a large collection of reference entries and mark them up appropriately. We are eagerly awaiting such a marvelous algorithm. However, in our particular circumstances, digital humanities is about developing methods and tools that leverage accessible and affordable competencies and resources in order to reach a practical goal cost-effectively. In this case, it will curate (and thus save) a vital piece of Danish cultural heritage, resulting in a new digital resource usable by anyone with an interest in the origin and history of place names in Denmark, and providing Denmark’s place-name authorities with a modern repository for future place-name registration and research (the first, rough presentation of which can be viewed at http://danmarksstednavne.navneforskning.ku.dk/).
Since the task had been deemed ‘highly complex’ by the vendors we had approached, we put some effort into the analysis. This paper presents the analysis, along with some ‘mid-term’ results since we have now parsed approximately 50% of the source material.
To date, approximately two thirds of Denmark is covered by the DS publication, which spans 25 (soon to be 26) volumes published in the period from 1922 to 2006. The individual place-names articles list a selection of the earliest known source types, historical forms of the name, and pronunciations, and provide scholarly interpretations and annotation of the name’s origin and meaning. An example is given below.
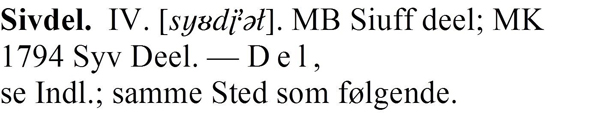 Figure 1: An entry in DS
Figure 1: An entry in DS
TEI Tite is a subset of the TEI created to standardize off-site text encoding somewhat, so that vendors and buyers can arrange for it by simply agreeing to adhere to TEI Tite at both ends. It captures all the printed material, all characters, and all structural divisions (like chapters, line breaks, etc.).
Given this, our initial data analysis showed us that it should be possible to parse individual ‘records’ (entries in DS) by ‘switching’ on typographical cues – for example, using the semi-colon character ‘;’ to differentiate between different source references, long hyphens to extract the interpretation, and so on.
The lexicography of the publication has never been formally specified, but it was quickly obvious that at least each individual volume had a fairly consistent lexicography; thus, a volume-by-volume parsing might reasonably succeed. Another practical problem was that since the publication has been ongoing for more than 90 years, the volumes exhibited small differences that are significant for parsing and must be dealt with individually.
The prospect of having to code 25 parsers gave us pause, however, so we set ourselves the task of producing a single program that could be configured from the outside to allow for (more or less) minute differences in lexicography and even new lexicographical instances – the roman numeral after the place name in Figure 1 was such an undiscovered item.
Very briefly stated, what we came up with is a modular, outside-of-code configurable, easily extended program/platform for parsing TEI Tite-formatted XML representations of dictionary or reference data, or textual data that exhibit ‘semantic typesetting’.
The general idea is that a module takes care of only one singular task in the whole parsing procedure, operates via a standard interface, and is callable outside the code via a configuration file.
The program is written in a modern high level programming language (C#) so that the skills needed to produce additional modules are readily available on most university campuses and in the population at large.
So: no super computers, no state-of-the-art statistical analysis, no genetic algorithms or natural language comprehension, no crowd-sourcing the production of new knowledge – at least not while digitizing existing sources of knowledge. Moreover, we claim no ‘new forms of scholarly inquiry’, not immediately at least, derived maybe, but not new and probably not that many new questions posed that could not have been answered albeit very laboriously before.
We do, however, believe that the methodology would likely add value to various TEI-encoded digital artifacts at not only a reasonable cost, but also by utilizing skills and competencies that are readily available. Billed hours for the parsing activity ended up in the low hundreds (~450 hours), so cost effectiveness would appear acceptable.
The paper presentation will present and discuss the following elements vital/interesting to the methodology.
- 80-20 The roughly 50.000 place name entries in DS are of more or less the same lexicography but of vastly differing length and complexity, so the program is designed to quickly pick up all ‘low hanging fruits’, parsing the simpler entries in their entirety and handing them off to the database team.
- Scoping of the modules Examples from the code will be presented to illustrate that there is almost no lower limit as to how little a single module should do. The salient point being the number of volumes that the module would be relevant for is more important than doing a lot of stuff all at once.
- When in doubt ask Another key element of the design is that every choice the program has to make is estimated as to how long it would take to produce working code versus simply asking the user/parser. As it turned out this principle has been the biggest time and cost saver on the project since it eliminates much of the risk of making the code brittle and having the programmer(s) take off on a quest for ‘a clever hack’™. Differentiating between source references and name instances will be demonstrated and discussed.
- Iterative, iterative, iterative Writing the parser modules proved to be at least as much data analysis as the, err, data analysis.
- Creating the framework and remembering what was done Taking into account item 4. above the framework was designed so it ‘remembers’ the steps taken on a given volume or subset of the publication so that ‘reparative’ steps/modules can be added on as they become evidently needed.
- Lessons learned
- Tools, as they are often envisioned in DH publications are most often ‘done deals’, completed software artifacts that can accomplish this thing or that with humanistic digital artifacts. The ‘tool’ this paper presents is the TEI Tite, a programming language and a methodology for putting the three together to achieve a specific end. As programming languages become more and more ‘user friendly’ the barrier to entry into this type of interactive, iterative, collaborative tool building lowers to the point where a project like ours became possible and this seems to be the way of the future.
- Also, last but verily not least: We believe that if it has lexicography, it can be parsed.
However, they are not stringent (database) schema and cannot be fully automatically parsed into such. Enter our technology/methodology for iteratively parsing lexicographically organized digital data (in the form of a TEI Tite encoded digitization).
The digital version of DS is paid for by the DigDag-project (www.digdag.dk)
From the DigDag website:
The DigDag project, short for Digital atlas of the Danish historical-administrative geography, is a research project funded by The National Programme for Research Infrastructure under the Danish Agency for Science, Technology and Innovation.
Running from 2009 to 2012, the aim of the project is the establishment of a database structure which can tie the Danish administrative districts together geographically and historically. This will provide a historical-administrative GIS platform for the digital humanities allowing to:
- establish a historical-administrative research infrastructure of Denmark c. 1600–
- form the backbone of future historical and administrative research
- create a powerful search engine for use in the service functions of archives, collections and libraries
As source data will be used Det digitale matrikelkort, the digital cadastre, and the basic unit will be the ejerlav, the townland.
Participants in the project are a range of major Danish research institutions with a focus on historical and administrative research together with the major Danish heritage institutions and archives.
References
Trolard, P. (2009). TEI Tite — A recommendation for off-site text encoding. http://www.tei-c.org/release/doc/tei-p5-exemplars/html/tei_tite.doc.html
DS 1922-2006. Danmarks Stednavne vol 1-25. Volumes 1-15 published by the Place Names Committee, Volumes 16-24 by the Department of Name Research, Volume 25 by the Department of Name Research at University of Copenhagen. See also http://da.wikipedia.org/wiki/Danmarks_Stednavne and/or http://nfi.ku.dk/publikationer/trykte_serier/danmarks_stednavne/
Bolter, J. D. (2001). Writing Space: Computers, Hypertext, and the Remediation of Print. Second Edition. Mahwah, NJ: Lawrence Erlbaum.
Levy, P. (1998). Becoming Virtual: Reality in the Digital Age. Da Capo Press.
Weinberger, D. (2002). Small Pieces Loosely Joined: A Unified Theory of the Web. New York: Perseus Publishing.
Lowy, J. (2005). Programming .NET Components: Design and Build .NET Applications Using Component-Oriented Programming. Sebastopol, CA: O’Reilly Media; 2 edition.