
Introduction
The surfaces and spaces of our planet, and particularly metropolitan areas, are not only manifestations of visible physical shapes, but also include dimensions that go beyond the ocular. Furthermore, these invisible energies are often in a state of flux and could potentially yield insights into the living and breathing dimensions of our surroundings that are underexplored in contemporary mapping research. The Citygram project explores and develops ideas and concepts for novel mapping paradigms that reflect aspects of dynamicity and ‘the invisible’ pertinent to cityscapes. The project’s main goal is to contribute to existing geospatial research by embracing the idea of time-variant, poly-sensory cartography. Our multi-layered and multi-format custom maps are data-driven and based on continuous data streams captured by remote sensors. These dynamic maps can inform us of the flux in our built environments, such as parks, museums, alleys, bus stations, freeways, and university campuses.
Citygram is a large-scale project divided into a number of manageable iterations. The current iteration focuses on visualizing acoustic ecology and computationally inferring meaningful information such as emotion and mood. We are currently focusing our attention on small public spaces at the following university campuses: Georgia State University and Georgia Institute of Technology in Atlanta; California Institute of the Arts in Los Angeles; and Massey University in Wellington, New Zealand. Our aim is to render dynamic, non-intrusive acoustic maps that are scale accurate and topologically oriented.
Current Mapping Paradigms and Technologies
The most commonly used mapping paradigms are represented by Google Maps and and Bing Maps (PC World 2010). Many supplemental features are provided by these platforms: street-views, webcams (1 frame/hour), and pre-recorded videos taken from locations. Other mapping systems, such as UCLA’s Hypercities (‘Hypercities’ 2010), BBC’s Save Our Sounds (‘Save Our Sounds’ 2011) and the Locus Stream Project (‘Locus Sonus > Locustream’ 2011) are more creative. Hypercities is an interactive mapping system that allows temporal navigation via layers of historic maps, which are overlaid on modern maps via the Google Earth interface. Save Our Sounds gathers crowd-sourced audio snapshots, archives them, and makes ‘endangered sounds’ available on a web interface. The Locustream SoundMap project is based on the notion of networked ‘open mic’ audio streaming where site-specific, unmodified audio is broadcast on the Internet through a mapping interface. It seems that the project has its roots in artistic endeavors where ‘streamers,’ persons who install the Locustream boxes in their apartments, share ‘non-spectacular or non-event based quality of the streams’ thereby revisiting a mode of listening exemplified by the composer John Cage.
Citygram One: Goals, Structure, and Focus
The project’s main goals are to (1) investigate potential avenues for capturing the flux of crowds, machines, ambient noise, and noise pollution; (2) map, visualize, and sonify sensory data; (3) automatically infer and measure emotion/mood in public spaces through sound analysis, pattern recognition, and text analytics; (4) provide clues to waves of contemplation and response in public spaces; (5) provide hints into the invisible dynamics between Citygram maps and aspects of urban ecology such as crime and census statistics, correlations to municipal boundaries, population density, school performance, real-estate trends, stock-market correlations, local, regional, national, and global news headlines, voting trends, and traffic patterns; (6) seek additional regional, national, and international collaborators.
Figure 1 shows the system overview. The data collecting devices (d) are small computers that wirelessly transmit feature vectors (v[n]) to a central server. The minicomputers autonomously run the signal processing modules for the optimal efficiency of the entire system. Low-level acoustic feature vectors streamed to the server are unintelligible and cannot be exploited to reconstruct the original audio waveforms or ‘eavesdrop’ on private conversations. This protects the privacy of individuals in public spaces. However, to enable users to hear the ‘texture’ of a space without compromising privacy we employ a modified granular synthesis techniques (Gabor 1946) which results in shuffling the temporal microstructure of audio signals.
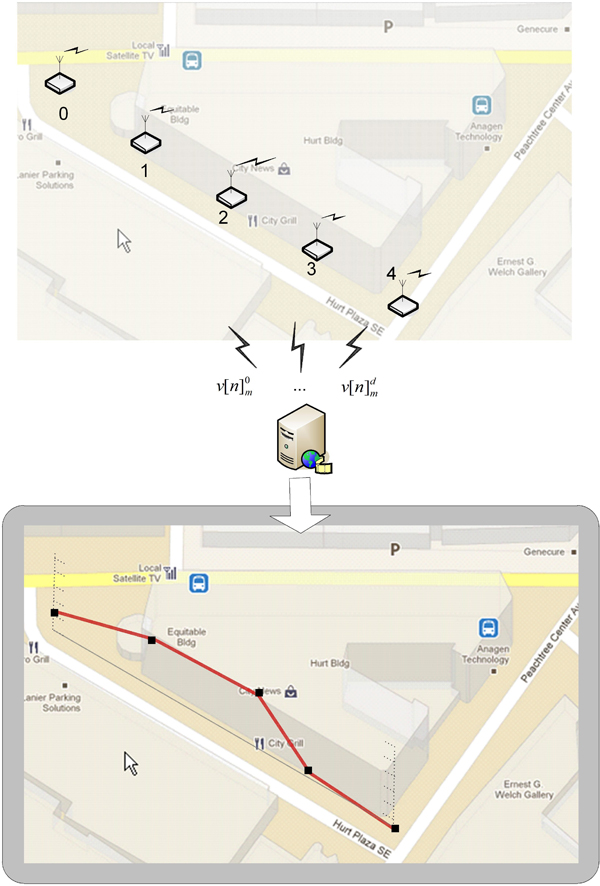
Figure 1: System architecture Top: Autonomous remote sensing devices transmitting feature vectors Bottom: Measurement of acoustic energy (dB)
Citygram focuses on inferring useful information from invisible energies. One type of avisual information is environmental emotion or mood. Although interdisciplinary sentiment research is still in its nascent stages, automatic mood detection has found increasing interest in the field of music (Liu et al. 2003; Wieczorkowska et al. 2006; Meyer 2007), speech analysis (Chuang & Wu 2004; Vidrascu 2005; Schuller 2008; Shafran 2011), face-recognition (Cohn & Katz 1998; Yoshitomi et al. 2000; Nagpal et al. 2010), and natural language processing (Xia et al. 2008; Tao 2004). As far as emotion detection in music is concerned, much of the research can be traced to Kate Hevner’s (Hevner 1936) seminal work in musical expression (see Figure 2) and other models developed by Thayer and Tellegen-Waston-Clark (Thayer 1989; Tellegen et al. 1999) as shown in Figure 3 and 4.
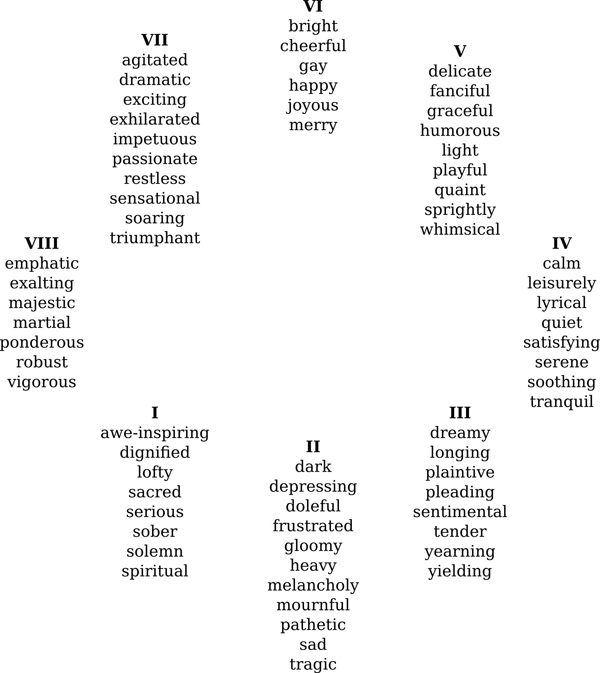
Figure 2: Hevner’s adjective circle
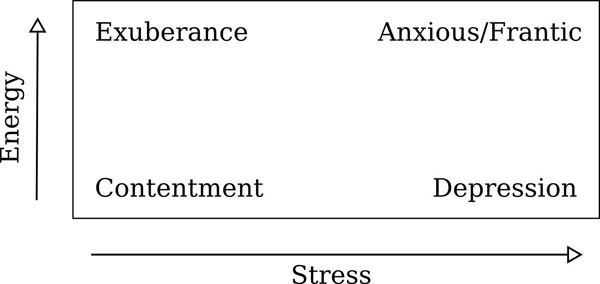
Figure 3: Thayer’s model of mood
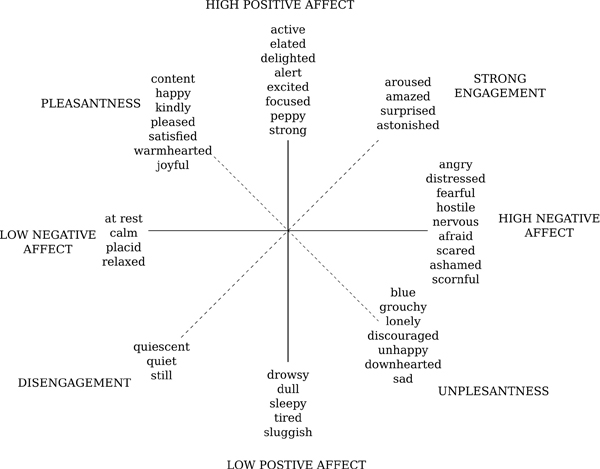
Figure 4: Tellegen-Waston-Clark mood model
Automatic Emotion Detection
The fundamental architecture of automatic emotion detection is shown in Figure 5. Features are extracted from audio signals, followed by training of the machine learning (ML) algorithms via a set of training samples; at the final stage, the machine classifies emotion ratings for unknown signals. Although much of the emotion/mood detection research for sound has been in the realm of music, there is strong potential that algorithms and methodologies similar to those used in music will translate to non-musical signals – many of the low-level feature vectors are timbral rather than musical and reflect acoustic dimensions of sound.
We are exploring application of radial and elliptical basis functions (RBF/EBF) artificial neural networks (ANN) for automatic emotion classification as it has shown promise in previous research (Park 2004; Park and Cook 2005). We plan to compare Support Vector Machines (SVM) with RBF/EBF ANNs as each is based on contrasting approaches – RBF/EBF is hyperspherical/hyperellipsoid based and SVM is hyperplane based. We are also investigating ‘knowledge-based’ approaches for automatic verbal aggression detection in acoustically complex social environments already in use in public spaces (van Hengel et al. 2007). Feature vectors will be archived on our server to provide users a hub for future research on public spaces.
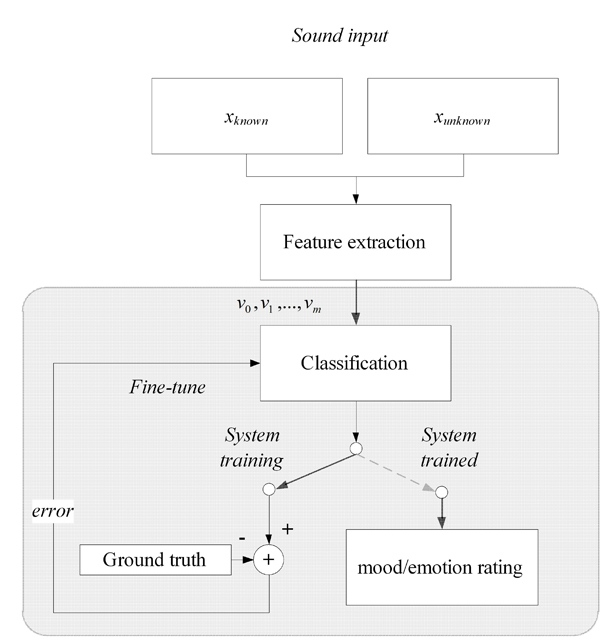
Figure 5: Mood/Emotion Detection Architecture
Natural language processing techniques will further enrich the project’s assessment of environmental sentiments via site-specific emotional readings from on-line sources. Recent examples of localized text sentiment visualization from blogs and micro-blogs can be found in ‘Pulse of the Nation’ (Mislove et al. 2010) and ‘We Feel Fine’ (Harris & Kamvar 2011). In conjunction with spatial acoustic emotion detection, this analysis will help us render comprehensive, dynamically changing emotion indices through our on-line visualization mapping formats. The general structure for sentiment analysis in the context of ML is similar to general practices in ML for sound; both apply algorithms aimed at revealing patterns through features. We are currently concentrating on keyword spotting (Ortony et al. 1987) supplemented by ‘common sense reasoning.’ Keyword spotting relies on a pre-established lexicon of scored, significant language. Common sense reasoning utilizes a database like Open Mind Common Sense (OMCS) to infer meaning from text. A toolkit like ConceptNet is used in conjunction with OMCS to facilitate sentiment analysis. This combination will allow us to recognize both pre-coded and emergent sentiments. For instance, a keyword approach utilizes lists of significant language and modifiers to recognize that ‘unhappy,’ preceded by ‘very,’ is more significant than just ‘unhappy’ by itself. Recognizing that a capitalized or exclamatory modifier, i.e.’VERY!!,’ accentuates the keyword and intensifies its positive or negative valence (intrinsic attractiveness vs. aversiveness) scale, requires OMCS.
This research, to better understand the dynamic life and mood of urban spaces via acoustic ecology, mapping, pattern recognition, and data visualization, is the first iteration in the larger Citygram project. Subsequent iterations of this project will include analyzing additional types of avisual energies, such as electromagnetic fields, humidity, temperature, color, and brightness and extending this dynamic, poly-sensory cartographic data into a resource for inquiry on topics ranging from urban ontology and climate change to sonification, and environmental kinetics.
References
Baum, D. (2006). Emomusic – Classifying Music According to Emotion. Proceedings of the 7th Workshop on Data Analysis, Kosice, Slovakia, July 2009.
British Broadcasting Corporation (2011). Save Our Sounds. http://www.bbc.co.uk/worldservice/specialreports/saveoursounds.shtml (accessed 10 October 2011).
Chuang, Z., and H. Wu (2004). Multi-Modal Emotion Recognition from Speech and Text. International Journal of Computational Linguistics and Chinese Language Processing 9(2): 45-62.
Cohn, J., and G. Katz (1998). Bimodal Expression of Emotion by Face and Voice. Proceedings of the Sixth ACM International Multimedia Conference, New York, NY, September 1998.
Cohn J., and G. Katz (1998). Workshop on Face / Gesture Recognition and Their Applications. Proceedings of the Sixth ACM International Multimedia Conference, New York, NY, September 1998.
Davies, A. (2011). Acoustic Trauma : Bioeffects of Sound. Honors Thesis, University of South Wales.
Devillers, L., V. Laurence, and L. Lori (2005). Challenges in Real-Life Emotion Annotation and Machine Learning Based Detection. Neural Networks 18(4): 407-422.
Fragopanagos, N., and J. Taylor (2005). Emotion Recognition in Human-Computer Interaction. Neural Networks 18(4): 389-405.
Gabor, D. (1946). Theory of Communication. Journal of the Institute of Electrical Engineers 93: 429-457.
Gupta, P., and N. Rajput (2007). Two-Stream Emotion Recognition for Call Center Monitoring. Proceedings of Interspeech, Antwerp, Belgium, August 2007.
Harris, J., and S. Kamvar (2011). We Feel Fine and Searching the Emotional Web. Proceedings of the Web Search And Data Mining Conference, Hong Kong, China, November 2011.
Hevner, K. (1936). Experimental Studies of the Elements of Expression in Music. American Journal of Psychology 48: 246-268.
Kessous, L., G. Castellano, and G. Caridakis (2004). Multimodal Emotion Recognition in Speech-Based Interaction Using Facial Expression, Body Gesture and Acoustic Analysis. J Multimodal User Interfaces 3: 33-48.
Li, T., and M. Ogihara (2003). Detecting Emotion in Music. Proceedings of the International Society for Music Information Retrieval, Baltimore, Maryland, October 2003.
Li, T., and M. Ogihara (2004). Content-Based Music Similarity Search and Emotion Detection. Proceedings of the International Society for Music Information Retrieval, Quebec, Canada, May 2004.
Liu, D., L. Lu, and H. Zhang (2003). Automatic Mood Detection from Acoustic Music Data. Proceedings of the International Society for Music Information Retrieval, Baltimore, Maryland, October 2003.
Liu, H. (2002). Automatic Affective Feedback in an Email Browser. In MIT Media Lab Software Agents Group.
Liu, H., H. Lieberman, and T. Selker (2003). A Model of Textual Affect Sensing Using Real-World Knowledge. International Conference on Intelligent User Interfaces, Miami, FL, January 2003.
Liu, H., and P. Singh (2004). Conceptnet: A Practical Commonsense Reasoning Toolkit. BT Technology Journal 22: 211-26.
Locus Sonus (2008). LocusStream. http://locusonus.org/w/?page=Locustream. (accessed 10 October 2011).
Meyers, O. C. (2007). A Mood-Based Music Classification and Exploration System. Master’s thesis, Massachusetts Institute of Technology.
Mislove, A., S. Lehmann, and Y. Ahn (2010). Pulse of the Nation: U.S. Mood Throughout the Day Inferred from Twitter. http://ccs.neu.edu/home/amislove/twittermood/. (accessed 1 November 2011).
Nagpal, R., P. Nagpal, and S. Kaur (2010). Hybrid Technique for Human Face Emotion Detection. International Journal of Advanced Computer Science and Applications 1(6).
Null, C. (2010). Which Online Mapping Service Is Best? PC World. http://www.pcworld.com/article/206702-2/which_online_mapping_service_is_best.html. (accessed 30 October 2011).
Ortony, A., G. L. Clore, and M. A. Foss (1987). The Referential Structure of the Affective Lexicon. Cognitive Science 11: 341-364.
Park, T. H. (2004). Towards Automatic Musical Instrument Timbre Recognition. Ph.D. thesis, Princeton University.
Park, T. H., and P. Cook (2005). Radial/Elliptic Basis Functions Neural Networks for Musical Instrument Classification. Journées d’Informatique Musicale.
Presner, T. (2010). Hypercities: Building a Web 2.0 Learning Platform. In A. Natsina and T. Kyalis (eds.), Teaching Literature at a Distance.London: Continuum Books, pp. 171-182.
Schnaps, J. (2009). Age and Clarity of Imagery. http://sites.google.com/site/earthhowdoi/Home/ageandclarityofimagery (accessed 10 October 2011).
Schuller, B. W. (2008). Speaker, Noise, and Acoustic Space Adaptation for Emotion Recognition in the Automotive Environment. Proceedings of ITG Conference on Voice Communication (SprachKommunikation), pp. 1-4.
Shafran, I., and M. Mohri (2005). A Comparison of Classifiers for Detecting Emotion from Speech. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, May 2005.
Singh, P., T. Lin, E. Mueller, G. Lim, T. Perkins, and W. Zhu (2002). Open Mind Common Sense: Knowledge Acquisition from the General Public. Lecture Notes in Computer Science, pp. 1223-1237.
Tao, J. (2004). Context based emotion detection from text input. Proceedings ofInternational Conference on Spoken Language Processing, Jeju Island, Korea, October 2004.
Tellegen, A., D. Watson, and L. A. Clark (1999). On the dimensional and hierarchical structure of affect. Psychological Science 10: 297-303.
Thayer, R. (1989). The Biospychology of Mood and Arousal. Cambridge: Oxford UP.
van Hengel, P., and T. Andringa (2007). Verbal aggression detection in complex social environments. Fourth IEEE International Conference on Advanced Video and Signal Based Surveillance, London, United Kingdom, September, 2007.
Vidrascu, L., and L. Devillers (2005). Annotation and detection of blended emotions in real human-human dialogs recorded in a call center. Proceedings of the IEEE International Conference on Multimedia and Expo, Amsterdam, Netherlands, July 2006.
Wieczorkowska, A., P. Synak, and Z. W. Ras (2006). Multi-Label Classification of Emotions in Music. Intelligent Information Processing and Web Mining 35: 307-315.
Xia, Y., L. Wang, K. Wong, and M. Xu (2008). Sentiment vector space model for lyric-based song sentiment classification. Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies: Short Papers, Association for Computational Linguistics, Stroudsburg, PA, USA.
Yoshitomi, Y., S. I. Kim, T. Kawano, and T. Kitazoe (2000). Effect of Sensor Fusion for Recognition of Emotional States Using Voice, Face Image and Thermal Image of Face. IEEE International Workshop on Robot and Human Interactive Communication, Osaka, Japan, September 2000.