
Introduction
For centuries, scholars have been searching for reliable methods to establish the authorship of a work. The underlying premise of this scholarship is that each author has a detectable individual style of writing that can be explored with automated methods.
A range of features have been explored that include function words and character n-grams either individually or in combination with other features (Burrows 1987; Bayeen et al. 2002; Keselj et al. 2003; Argamon & Levitan 2005; Houvardas & Stamatatos 2006), part-of-speech information (Stamatatos et al. 2001), probabilistic context-free grammars (Raghavan et al. 2010), and linguistic features of the text (Koppel et al. 2006). Although many of those experiments consider only lexical features, syntactic features are considered more reliable (Stamatatos 2009: 542), but parsing technologies have only recently achieved the accuracy necessary to consider syntactic features in detail. Once the features are in place, the problem of authorship attribution can be cast as a classification problem and machine-learning methods can be used, such as Naïve Bayes or Support Vector Machine (SVM) that both work well when there are a large number of weak features. For very large collections and for open authorship attribution sets, similarity-based methods are more appropriate than machine-learning methods (Koppel et al. 2011).
Our goal is to analyze the potential of syntactic dependencies to characterize an author’s writing style with respect to how an author refers to people. The features that we use are drawn from both semantic and syntactic features. Specifically we first identify personal names – a semantic feature – and then identify local dependencies that surround those personal names – a syntactic feature. Our results demonstrate that these features vary between authors and that those variations can be exploited to accurately determine authorship attribution.
Method
The proposed authorship attribution model emphasizes how an author refers to people. This approach leverages linguistically motivated markers and takes advantage of recent automated methods to identify syntactic dependencies. Consider the following sentence shown in Figure 1: ‘Robert Ryan is the prey he captures, along with the girl Janet Leigh’ where author 819382 uses a noun appositive to refer to the actress Janet Leigh. Note that there are two structures in this case – one for Janet Leigh and another for Robert Ryan where the author uses the actor as the subject of the sentence. Our method considers one dependency before and one dependency after the person reference. Author 819382’s profile suggests a preference for appositives, such as in the sentence ‘The claims manager, Lee J. Cobb here, unravels the plot’ where the author again uses the appositive when referring to the character Lee J.Cobb.
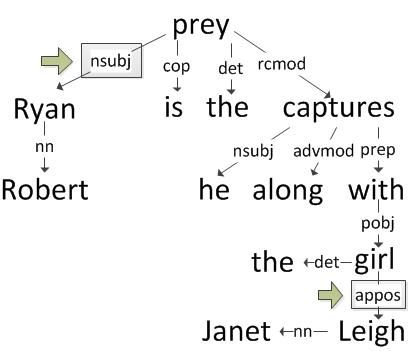
Figure 1: Dependency Grammar showing Robert Ryan as the subjects and Janet Leigh as a noun appositive
In contrast to author 819382, author 463200 prefers to describe several people together such as in the following examples that occur in different reviews: ‘Lois Lane and Clark Kent are sent to cover a circus (for some reason)’and ‘And there’s Gloria DeHaven and June Allyson in bit parts!’ (see Figure 2 for the dependency grammar representation). The coordination (cc) and preposition (prep) would also be used as candidate markers for this sentence.
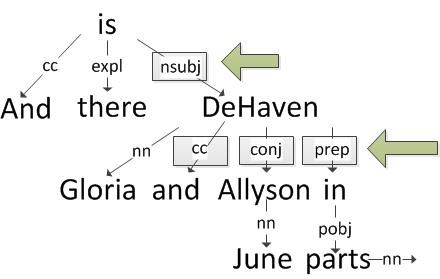
Figure 2: Dependency Grammar showing Gloria DeHaven as the subject and June Allyson in a conjunctive clause
Author 1609079, however, is more likely to use a nominal subject passive grammatical relation when introducing personal names than other reviewers. Figure 3 shows this pattern when referring to Evelyne in the context of the sentence ‘Arnold’s wife Evelyne is also expected to sacrifice for Edward.’ As with the earlier authors, author 1609079 uses other patterns in addition to nominal subject passive before the name within the same sentence. The generated author’s profile reflects all of these preferences and is thus well suited to use in discerning one author from another.
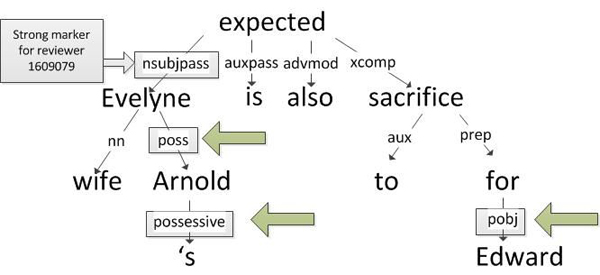
Figure 3: Dependency Grammar of a sentence by author 1609079 who prefers to refer to people as the subject of a passive clause
These examples provide the motivation for our strategy to use local syntactic structures where authors refer to people. The general approach to create an author profile has the following steps. The information shown in parenthesis provides details for the experiments reported in this paper.
- Collect and identify sentences from the source collection (Natural Language Toolkit recognizer, nltk.org
- Identify people within each sentence (Named Entity Recognizer, nlp.stanford.edu/software/CRF-NER.shtml)
- Generate syntactic dependency trees from each sentence (Stanford Lexical Parser version 1.6.9, nlp.stanford.edu/software/lex-parser.shtml)
- Align the person names with the dependencies and count the local grammatical structures before and after each person reference
- Normalize the local grammatical structures by dividing by the number of people used by an author
Our method only considered those sentences and only those reviews which included personal names and that had 80 or fewer words. Of the 62,000 reviews, 92% or 57,286 included at least one sentence that satisfied this criterion and of the 919,203total sentences 354,389 referred to people.
Results
The evaluations presented in this paper are based on a closed set of 62 candidate authors. The publicly available IMDb62 dataset (Seroussi et al. 2011) was harvested from the IMDB (imdb.com) in 2009 and satisfies Grieve’s (2007) requirement that the texts should be written in the same genre and should have originated around the same period. The IMDb62 collection, however, does not satisfy Grieve’s requirement that the texts should preferably be on the same topic as the movie review topics depend on the topic and genre of the movie. Only those reviewers who made prolific contributions to the imdb.com web site were selected for inclusion in the dataset so that each of 62 reviewers has 1,000 reviews (the total of 62,000 reviews). Movie reviewers typically refer to actors, directors and characters from a movie, so the IMDb62 dataset provides a rich collection in which to explore authorship style when referring to people.
Results show that authors differ both with respect to the number of person references made and how they refer to people. The majority of authors in the collection (43/62) referred to between 5,000 and 20,000 personal names in all of the reviews, but 15 authors use far fewer names (between 1,086 and 5,000), and 4 reviewers referred to more than 20,000 personal names (up to 33,115). Twenty-nine candidate syntactic features (13 before and 16 after personal names) were selected based on the frequency of use within the entire set of reviews. The two most frequent syntactic patterns before a personal name were nominal subject and object of a preposition while the most frequent syntactic patterns after a personal name were a punctuation mark and possessive modifier.
To evaluate how well the syntactic features could predict the correct author for a review, a test set was created by drawing 5% of reviews for each author at random from the original collection. The author profile described in the methods section was then created using the remaining 95% of the reviews (the training set) and the cosine similarity between the features in the test set and the profile in the training set was used to identify the correct author, i.e. if syntactic features are well suited to authorship disambiguation then the cosine similarly would place the correct author first in the ranked list of candidate authors. Note that all reviews in the test set (approximately 50) were considered together rather than as 50 different reviews and that this process was repeated 10 times with 10 different samples. On average the correct author appeared at rank 1.84 (in the range from 1 to 6.8). Twenty-one of the 62 authors are ranked first and author accuracy increases from 33.8, 67.7, 83.9 and 95.2% as the rank increases from 1 through 4.
With respect to related work, Seroussi et al. (2011) used Latent Dirichlet Allocation (LDA) to model topics within the IMBDb62 dataset and then authorship attribution is calculated by finding the smallest Hellinger distance between the test and training documents. Author attribution accuracy varied between 19 to 68% for the multi-document approach and 25 to 81% for a single-document approach depending on how many topics were used in the model. Seroussi et al.’s experiment (2011) outperformed the KOP method (Koppel et al. 2011) on the IMDb62 dataset by about 15% at 150 topics and the results were statistically significant.
Closing Comments
We have presented a new method that leverages local syntactic dependencies to reveal the ways in which an author refers to people. One limitation of this approach is that it is restricted to only those texts and those reviews which contain named entities (in our case personal names); however, authors frequently refer to people and places in history books, historical novels, and fiction works in general. Our preliminary results on the IMDb62 collection are consistent with Stamatatos’s speculation (2009) and indicate that grammatical structures , in our case that surround personal names, are indeed useful to differentiate between authorship styles. We posit that further experimentation is required to better understand how individual features, and combinations of features can best be used to determine authorship attribution accurately.
References
Argamon, S., and S. Levitan (2005). Measuring the Usefulness of Function Words for Authorship Attribution. Proceedings of the 2005 ACH/ALLC conference. Victoria, BC, Canada, June 2005.
Burrows, J. F. (1987). Computation into Criticism: A Study of Jane Austen’s Novels and an Experiment in Method. Oxford: Clarendon Press.
Grieve, J. (2007). Quantitative Authorship Attribution: An Evaluation of Techniques. LLC 22(3): 251-270.
Houvardas, J., and E. Stamatatos (2006). N-Gram Feature Selection for Authorship Identification. AIMSA 2006: 77-86.
Keselj, V., F. Peng, N. Cercone, and C. Thomas (2003). N-gram-based Author Profiles for Authorship Attribution. Proceedings of the Conference Pacific Association for Computational Linguistics. Dalhousie University, Halifax, Nova Scotia, Canada, August 2003.
Koppel, M., N. Akiva, and I. Dagan (2006). Feature instability as a criterion for selecting potential style markers: Special Topic Section on Computational Analysis of Style. Journal of the American Society for Information Science and Technology 57(11): 1519-1525.
Koppel, M., J. Schler, and S. Argamon (2011). Authorship Attribution in the Wild. Language Resources & Evaluation 45(1): 83-94.
Raghavan, S., A. Kovashka, and R. Mooney (2010). Authorship Attribution Using Probabilistic Context-Free Grammars. Proceedings of the ACL 2010 Conference Short Papers. Uppsala, Sweden, July 2010.
Seroussi, Y., I. Zukerman, and F. Bohnert (2011). Authorship Attribution with Latent Dirichlet Allocation. CoNLL 2011: Proceedings of the 15th International Conference on Computational Natural Language Learning. Portland, OR, USA, June 2011.
Stamatatos, E. (2009). http://onlinelibrary.wiley.com/doi/10.1002/asi.21001/fullA Survey of Modern Authorship Attribution Methods. Journal of the American Society for Information Science and Technology 60(3): 538-556.
Stamatatos, E., N. Fakotakis, and G. Kokkinakis (2001). Computer-Based Authorship Attribution without Lexical Measures. Computers and the Humanities: 193-214.