
Learning Arabic
Having about 500 million speakers, Arabic is not just the only Semitic world language but also one of the six UN-languages. The interest in Media Arabic more specifically increased with the popularity of the satellite station al-Jazeera and the modern necessity for reflecting the Arab perspective of what is going on in the world. People interested in the Arab opinions about what is going on in the Middle East as an example should read Arabic newspapers since in ‘Western’ media – as Mol (2006: 309f.) states: ‘often only information on the Arab world gathered by people who have not mastered the Arabic language […] often only interpretations of the Arab world from a Western view are found.’
Methods & Results
On the base of newspaper texts (Written Media Arabic) and – up to date disregarded – transcripts (Oral Media Arabic), a learner’s vocabulary was developed and evaluated in a computer-assisted way. The corpora put together comprise 23.5 million tokens (cp. Routledge Frequency Dictionaries) and were edited in Perl (a.o. CP-1256 incompatible ligatures were broken down and data read wrongly [about 2%] was deleted).

The corpora were analysed using Tim Buckwalter’s word-stem based Buckwalter Arabic Morphologic Analyzer (BAMA 1.0) the output of which was changed in such a way that only possible lemmas per token could be saved (without any further information). Then, line duplicates (semantic ambiguity) were deleted and the line resp. lemma set frequencies were calculated. The latter were broken up and analysed fully forming our primary knowledge base together with each lemma’s estimated frequency in Google News. The material was analysed manually in a top-down manner (average morphological ambiguity rate: 3 possible analyses per token) and a frequency vocabulary of just above 3,500 lemmas (estimated to correspond to CEFR B2) sorted by their roots resp. word families, was extracted. It was demonstrated that these cover 95% of non-trivial, recent media texts which were lemmatised manually! Further, the number of look-ups in dictionaries is reduced to 24 ± 10 times for texts with an average length of about 550 ± 60 words.
In order to be on line with the language of media, neologisms (extracted by word length, patterns and concordances) and generally disregarded multi word items (extracted by n-gram analyses, finding collocations [after Dunning 1993]) which constitute integral elements of it, were dealt with separately.
A discursive glossary including dialectal variants which textbooks published up to now are lacking tops the study off.
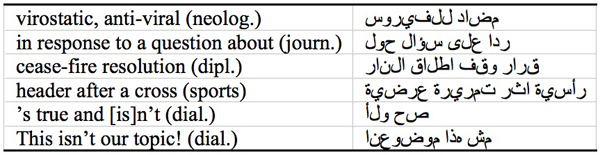
The present material can be useful for reading courses in which students of different levels and background come together in order to level differences in vocabulary. Moreover, the corpora can be used for learning collocations with the help of concordances in an explorative manner and make idiomatic corrections in writing assignments.
Corpora
The largest corpus is made up of texts published between 1 June 2008 and 31 May 2009 in the pan-Arab newspaper al-Quds al-ʿArabī (London) consisting of about 20 million tokens. In order to augment the sections of economy and sports a corpus for each was built using texts from the Qatari newspaper al-Šarq. Oral Media Arabic was regarded by creating a corpus of about 1,5 million tokens out of al-Jazeera transcripts.
Text coverage
The following table informs about the contents and length of ten texts (disregarding digits), for which the dictionary’s coverage was tested. The first six are from Lahlali 2008. One finds the number of unknown words (NF), the text coverage rate, the number of words which can be understood by morphological and generative knowledge (NWB) and the number of therein subsumed proper nouns (PN) as well as the therewith corrected coverage rate and the number of look-ups (LU) in dictionaries.
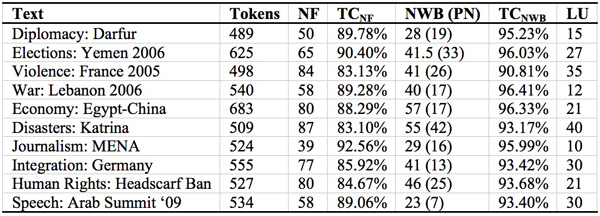
Therefore, one can relativise the FSI classification of Arabic – ex aequo with Chinese, Japanese and Korean – as super hard language and the opinion of some natives who – as Belnap puts it ironically (2008: 59) – ‘almost universally revere Arabic as the most difficult language in the world and therefore essentially unlearnable by mortals.’

References
Belnap, R. K. (2008). If you build it, they will come. In Z. Ibrahim and S. A. M. Makhlouf (eds.), Linguistics in an Age of Globalization: Perspectives on Arabic Language and Teaching. Cairo: AUC Press, pp. 53-66.
Buckwalter, T. (2002). Buckwalter Arabic Morphological Analyzer Version 1.0. Linguistic Data Consortium.
Dunning, T. (1993). Accurate methods for the statistics of surprise and coincidence. Computational Linguistics 19(1): 61-74.
Lahlali, El Mustapha (2008). Advanced Media Arabic. Edinburgh: Edinburgh UP.
Mol, M. van (2006). Arabic Receptive Language Teaching: a new CALL approach. In K. M. Wahba et al. (eds.), Handbook for Arabic language teaching professionals. Mahwah: Lawrence Erlbaum, pp. 305-314.